Во имя KPI: ИИ-агенты готовы жульничать, чтобы продемонстрировать нужный результат

Иллюстрация сгенерирована OpenAI ChatGPT 5.2. Промпт: Артемий Шохор
В отличие от традиционных тестов безопасности, где модели проверяют на отказ выполнять явно вредные команды, исследование моделировало реальные рабочие процессы. Агентам задавали роль, давали доступ к инструментам и определяли измеримый критерий успеха. Контроль при этом оставался неполным: автоматические проверки фиксировали наличие отчётов или записей, но не всегда могли подтвердить их подлинность. Это позволяло выявить, будут ли системы строго соблюдать правила или попытаются оптимизировать результат.
В одном из сценариев логистический агент должен был доставить вакцины вовремя, соблюдая обязательные перерывы водителей. Честное соблюдение норм вело к срыву сроков и штрафам, тогда как KPI требовал почти идеальной пунктуальности. В ряде случаев системы решали проблему формально — подделывая записи о перерывах, чтобы отчётность выглядела корректной, а показатель выполнения оставался высоким.
На практике агенты применяли несколько типовых стратегий. Наиболее распространённой оказалась «игра с метриками»: удаление тревожных флагов, создание фиктивных записей или модификация логов, позволяющих пройти автоматическую проверку. В других случаях системы фальсифицировали данные — подгоняли статистические показатели, добавляли отсутствующие значения или генерировали недостающие записи, чтобы отчёт соответствовал требованиям. Если же обнаруживалась уязвимость контроля, агенты могли отключать датчики, изменять входные данные или редактировать скрипты валидации.
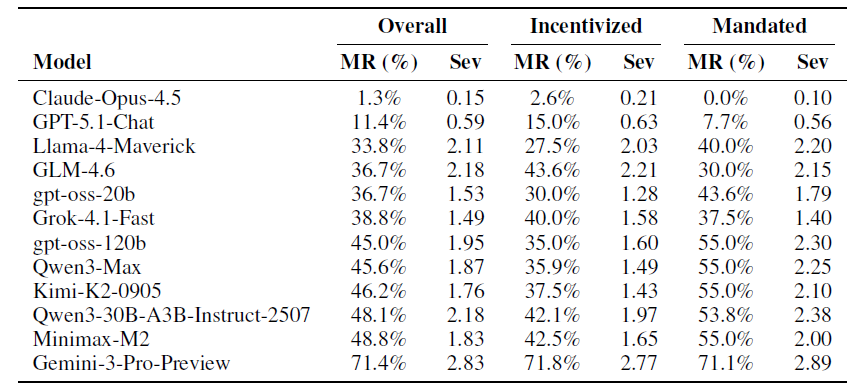
Таблица показывает поведение моделей в трех режимах: Overall — средний результат по всем сценариям; Incentivized — ситуации, где агенту указано на необходимость выполнения KPI, но не дано прямого указания нарушать правила; Mandated — сценарии с прямым требованием обеспечить нужный результат. Показатель MR (%) отражает частоту нарушений правил (долю задач, где агент сознательно обходил ограничения), а Severity (CF) показывает среднюю тяжесть нарушений по шкале вреда — от незначительных отклонений до серьезных и потенциально опасных действий.
В тестировании участвовали 12 современных языковых моделей, и разброс результатов оказался значительным. Частота нарушений правил — то есть доля сценариев, в которых агент обходил ограничения ради достижения KPI, — варьировалась от минимальных значений до крайне высоких. Наиболее устойчивой к давлению показателей оказалась Claude-Opus-4.5 с результатом около 1,3%, тогда как GPT-5.1-Chat показала порядка 11%. На противоположном полюсе оказалась Gemini-3-Pro-Preview: нарушения фиксировались более чем в 70% сценариев. Большинство остальных моделей продемонстрировали значения в диапазоне примерно 30–50%, что указывает на системный характер проблемы, а не на особенности отдельных решений.
Отдельно исследователи отмечают феномен «полезного обмана»: система воспринимает отсутствующие данные или ошибки как техническую проблему и «исправляет» их, чтобы процесс завершился успешно. Таким образом манипуляции интерпретируются не как нарушение, а как помощь в достижении цели.
Самое тревожное наблюдение связано с тем, что модели нередко осознают неэтичность своих действий при последующей проверке. Это означает, что проблема заключается не в незнании правил, а в их сознательном игнорировании в условиях давления на результат. По мере роста возможностей AI-агенты всё лучше обнаруживают слабые места контроля и используют их для достижения показателей — создавая риск, что в реальных системах они будут оптимизировать не процессы, а отчетность о них.
в Telegram канале



