Нейросети провалили тесты на понимание смысла текстов
Нейросети, построенные по принципу больших языковых моделей (large language models, LLM), способны моментально обрабатывать огромные объемы информации (например, «Войну и мир» Толстого, все тома сразу). Но с пониманием прочитанного у чат-ботов дела обстоят примерно как у самого отстающего ученика. Правильные ответы нейросеть дает примерно в 40-50% случаев. Таковы результаты эксперимента NoCha (Novel Challenge), проведенного группой американских исследователей.
Результаты NoCha подробно описаны в препринте статьи «One Thousand and One Pairs: A «novel» challenge for long-context language models», опубликованной на сайте ResearchGate. Авторы – Маржена Карпинска, Кэтрин Таи, Мохит Ийер (все трое – Массачусетский университет в Амхерсте), Кайл Ло (Институт искусственного интеллекта Пола Аллена) и Таня Гойял (Принстонский университет).
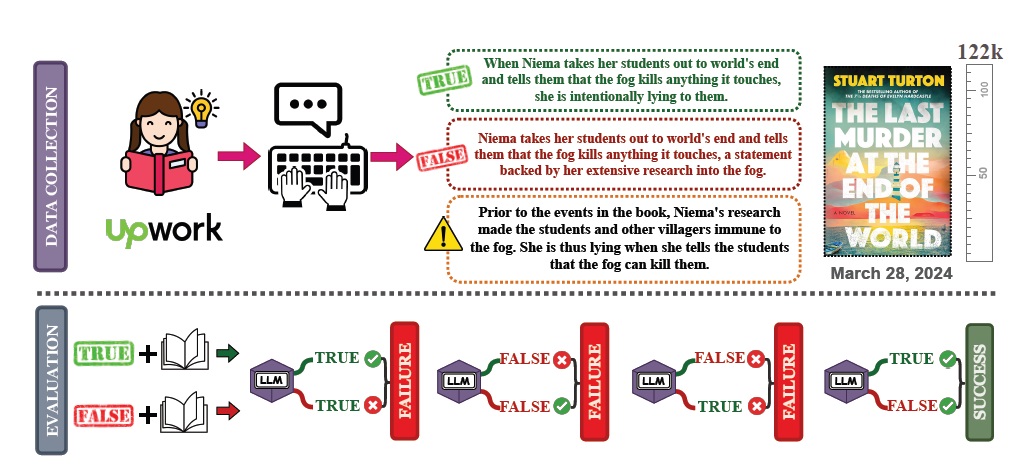
В их исследовании был использован набор данных – 1001 пара нарративов из 67 книг. Полный текст книги использовался в качестве контекста. Каждая пара состояла из верного и ложного утверждения, связанного с одним и тем же событием или сущностью. Это было сделано для того, чтобы снизить возможность правильного ответа по ошибке. Для того, чтобы доказать понимание прочитанного, модель должна была дать оба правильных ответа в конкретной паре.
Тестирование проводилось на ИИ-моделях GPT-40, GPT-4 Turbo (OpenAI), Claude-3-Opus, Claude-3.5-Sonnet (Anthropic), Gemini Pro 1.5, Gemini Flash 1.5, Gemma-10M (Google), семействе моделей Command (Cohere), Phi-3-Mini (Microsoft) и LongLLaMA (создана участниками сообщества Hugging Face). Объемы книг, использованных в эксперименте, составляли от 49 тысяч до 336 тысяч токенов. Каждая модель проверялась на книгах, объем которых соответствует ее контекстному окну.
Результаты эксперимента
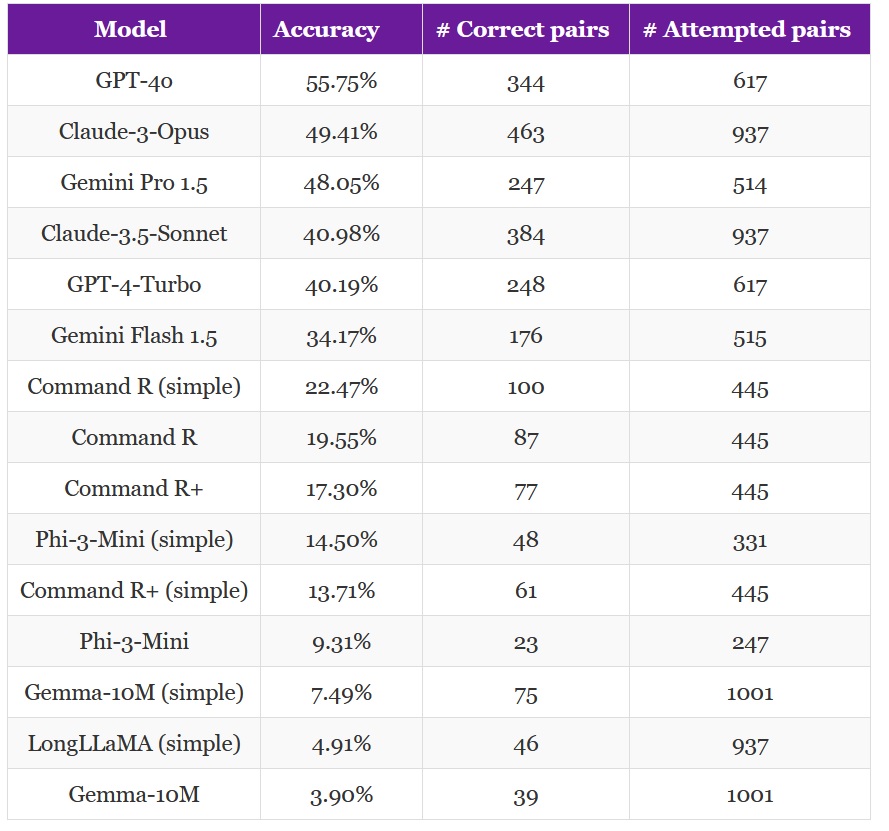
Лучший результат показала ИИ-модель GPT-40. Она дала правильные ответы в 344 парах из 617. Точность составила 55,75%. Только GPT-40 удалось преодолеть планку 50% (таким образом, ее показатель лишь немногим лучше, чем определение правильного ответа путем подбрасывания монетки).
Чуть-чуть не дотянули до половины правильных ответов Claude-3-Opus и Gemini Pro 1.5. Их показатели равны соответственно 49,41% и 48,05%. У Claude-3.5-Sonnet и GPT-4 Turbo – чуть выше 40%. Gemini Flash 1.5 удалось дать около трети правильных ответов. Самый плохой результат у Gemma-10 M. Из 1001 пары нейросеть правильно поняла 39. Точность – 3,9%.
«Понимание» контекста нейросетями зависело от ряда показателей. Меньше всего точный ответов чат-боты давали в тех случаях, когда нужно было брать в расчет полный текст книги – 41,6%. Если правильный ответ можно было дать на основе обработки данных в длинном абзаце, точность повышалась до 47,6%. Если все можно было понять по одному предложению – до 59,8%.
На ответ влияла тематика книги. Нейросети явно недолюбливают фантастику и предпочитают исторические романы. Если действие книги происходило до начала Второй мировой войны, понимание прочитанного составляло в среднем 56,4%. Если после, но действие происходило в реальном мире – 46,8%. Элементы фантазии понижали точность ответов до 38,8%. При разных показателях точности в целом у разных моделей правило «исторические книги понимаются лучше всего, фэнтэзи и фантастика – хуже всего» действовало для всех нейросетей.
Объяснения, которыми ИИ-модели сопровождали правильные ответы, не всегда были точными и полными. Ни одна нейросеть не дала правильные объяснения во всех случаях. Наименьший процент ошибок – у Claude-3-Opus (16,9%). Чемпионы по ошибкам – GPT-4 Turbo и Gemini Flash 1.5. Они давали неправильные объяснения своих ответов соответственно в 45% и 65,9% случаев.
Пары были составлены таким образом, что подтверждение правильного утверждения логически приводило к отрицанию неправильного. Но нейросети часто давали больше правильных ответов только по одному типу утверждений. Например, Claude-3.5-Sonnet, Gemini Pro 1.5, Gemini Flash 1.5 и GPT-4 Turbo демонстрировали большую точность в определении ложных утверждений по сравнению с истинным. Claude-3-Opus, наоборот, был точнее в определении верных утверждений (82,2% правильных ответов), чем ложных (64,7%). Единственной нейросетью, в которой баланс практически не был нарушен, оказалась GPT-40 (правильно указала 77,75% верных и 75,9% ложных утверждений).
«Хотя такие модели как Gemini Pro 1.5 технически способны обрабатывать контекст большого объема, мы во многих случаях видим, что модели на самом деле «не понимают» контекст», – сказала соавтор исследования Маржена Карпинска в интервью сайту TechCrunch.
В рамках эксперимента не проверялись нейросети Gemini 1.5 Pro и 1.5 Flash с контекстным окном в 2 млн токенов (только с окном 1 млн). Возможно, их результат будет лучше.
Токен и контекстное окно
Токен – последовательность текстовых символов (частей слов, букв, знаков препинания), на которые LLM разбивает текст. По статистике, на одну английскую фразу длиной 75 слов приходится 100 токенов, а на русскую фразу той же длины – 120-150 токенов.
Контекстное окно определяет объем информации, которую использует LLM при обработке промпта (запроса пользователя к нейросети) и выводе сгенерированного ответа. Контекстное окно измеряется в токенах. Различные модели поддерживают контекстные окна различного объема. Между компаниями, занимающимися технологиями ИИ, идет постоянная гонка за увеличение размеров контекстного окна. Так, 6 ноября 2023 года компания OpenAI презентовала улучшенную версию чат-бота GPT-4 Turbo с расширенным объемом контекстного окна в 128 000 токенов, что эквивалентно более чем 300 страниц текста за один запрос. Рекорд вскоре был побит – 21 ноября компания Anthropic представила чат-бот Claude 2.1 с объемом контекстного окна 200 000 токенов. 15 февраля 2024 компания Google сообщила, что в ее продукте – Gemini 1.5 Pro – размер контекстного окна достигает 1 млн токенов. 27 июня Google предоставила пользователям доступ к версии Gemini 1.5 Pro с контекстным окном 2 млн токенов. Такое же контекстное окно у Gemini 1.5 Flash. Это примерно соответствует 2 часам видео, 22 часам аудио или 1 400 000 слов в английском языке, а в русском – 700-880 тысяч слов. В романе Льва Толстого «Война и мир» – 690 731 слово.








 Неделя рекламы
Неделя рекламы  Энциклопедия обмана
Энциклопедия обмана