Главный конкурент OpenAI утверждает, что его нейросеть обогнала GPT-4o
В мире больших языковых моделей появился новый претендент на лидерство. Компания Anthropic, в прошлом году договорившаяся о многомиллиардных инвестициях с Amazon и Google, выкатила в четверг нейросеть Claude 3.5 Sonnet и утверждает со ссылкой на независимые тесты, что по ряду параметров она превосходит GPT-4o от OpenAI. Первые пользователи делятся в соцсетях впечатляющими кейсами, в которых Sonnet 3.5 помогает им решать самые разные задачи, экономя массу времени и усилий. Но несмотря на явно удачный продукт и прочно занятую позицию главной альтернативы сервисам OpenAI, выручка Anthropic пока в разы меньше, чем у главного конкурента.

Компактнее, быстрее и умнее
Компания Anthropic продолжает доказывать, что достижения OpenAI не уникальны, а разница в качестве работы между языковыми моделями лидеров отрасли становится пренебрежимо мала. Три месяца назад она выпустила на рынок семейство из трех моделей Claude 3 — компактной Haiku, средней Sonnet и большой Opus. 20 июня средняя модель получила обновление до версии 3.5. Как утверждают в Anthropic, ссылаясь на стандартные тесты, она пусть немного, но превосходит GPT-4o от OpenAI в большинстве задач. Одним из главных преимуществ новинки, как говорят ее разработчики, является способность понимать сложные и нюансированные инструкции, и даже юмор, с которым у ИИ традиционно большие проблемы.
В чем отличия «малых», «средних» и «больших» нейросетей
Языковые модели ИИ различаются по количеству параметров, используемых для их обучения, что и определяет их классификацию на малые, средние и большие. Малые модели не требуют больших вычислительных затрат, дешевы и подходят для базовых задач — автозаполнение текста, базового машинного перевода, ответов на простые вопросы. Некоторые из них могут работать даже на пользовательском железе, включая смартфоны. Средние обеспечивают баланс между производительностью и затратами, а самые большие, требующие значительных ресурсов, способны генерировать высококачественный контент и справляться с самыми сложными задачами — но и стоят гораздо дороже. Выбор модели зависит от целей и бюджета: малые — для простоты и экономии, средние — для оптимального соотношения цены и качества, большие — для максимальной точности и выдающихся результатов.
Claude 3.5 Sonnet умеет анализировать как текст, так и изображения, при этом генерирует только текст (в том числе в виде программного кода). Это самая производительная модель Anthropic на сегодняшний день — по крайней мере, на бумаге. По нескольким ИИ-тестам из области понимания текста, программирования, математики и компьютерного зрения новинка превосходит модель, которую она заменяет, Claude 3 Sonnet, и опережает предыдущую флагманскую модель Anthropic, Claude 3 Opus.
Особенно это заметно в визуальных задачах. Claude 3.5 Sonnet может точнее, чем Claude 3 Opus, интерпретировать диаграммы и графики и расшифровывать текст с некачественных изображений — например, фотографий с искажениями и визуальными артефактами. Это может быть важным, например, для ритейлеров, которые экспериментируют с использованием ИИ для видеоаналитики.
Майкл Герстенхабер, руководитель продукта в Anthropic, пояснил в интервью TechCrunch, что улучшения являются результатом архитектурных изменений и использования новых массивов данных для обучения. При этом, поскольку качественные и не защищенные авторским правом тексты для обучения нейросетей в интернете уже заканчиваются, в Anthropic начали применять для обучения и данные, сгенерированные ИИ. Но полностью раскрыть, на каких именно наборах данных обучали Sonnet 3.5, в Anthropic не готовы — не исключено, чтобы избежать возможных претензий со стороны правообладателей.
Есть у новой модели Anthropic и свои недостатки. Например, пользователи с удивлением обнаружили, что Sonnet 3.5 (в отличие от флагманских моделей OpenAI и Google) так и не научилась заходить на сайты по заданной ссылке и рассказывать, что видит на странице, или получать с них конкретную информацию. Правда, до некоторой степени это компенсируется тем, что новая модель обучена на максимально свежих данных — вплоть до апреля 2024 года, и может отвечать на вопросы по ним. Знания GPT-4o ограничены маем 2023 года, а GPT-4 Turbo — декабрем 2023-го.
Зато дешевле
Anthropic, по крайней сейчас, не может похвастаться какими-то уникальными преимуществами своей новейшей модели по сравнению с конкурентами. Например, Claude 3.5 Sonnet набирает 92% на тесте написания кода HumanEval против 90,2% у GPT-4o — это вряд ли достаточно весомый аргумент для отказа от продуктов общепризанного лидера, OpenAI, в пользу главного догоняющего. Поэтому в Anthropic смещают фокус в сторону более прагматичных вещей — стоимости и скорости работы.
Amazon уже открыла доступ к Claude 3.5 Sonnet клиентам своего облачного хостинга нейросетей Bedrock. В публикации в блоге Amazon Web Services сказано, что Claude 3.5 Sonnet работает с той же скоростью, что и Sonnet 3-го поколения, но обладает способностями Opus 3 при в пять раз меньшей стоимости использования. Заказчикам предлагают применять модель для чат-ботов клиентской поддержки, организации многоступенчатых рабочих процессов и оптимизации работы с программным кодом в масштабах всей компании.
«Для бизнеса важно, помогает ли ему ИИ достигать поставленных целей, а не то, как этот ИИ показывается себя в тестах в сравнении с конкурентами, — сказал Герстенхабер TechCrunch. — И с этой точки зрения я верю, что Claude 3.5 Sonnet станет на порядок лучше всех остальных наших моделей, и также впереди любого продукта в отрасли».
При использовании через API Anthropic, «облако» Amazon или Google Sonnet 3.5 стоит столько же, сколько и Sonnet 3 — $3 за миллион токенов (частей слова в 3-4 знака) в пользовательских запросах и $15 за миллион токенов в ответах нейросети. При этом Opus 3, которую новинка превосходит почти во всем, стоит в пять раз дороже. Аргументы Anthropic в пользу своей новой разработки компания решила поддержать наглядным графиком, на котором отражены способности выходивших в последние месяцы разных моделей с закрытым исходным кодом от ведущих игроков. На нем видно, что усредненный результат по 11 тестам для разных нейросетей со временем различается все меньше.
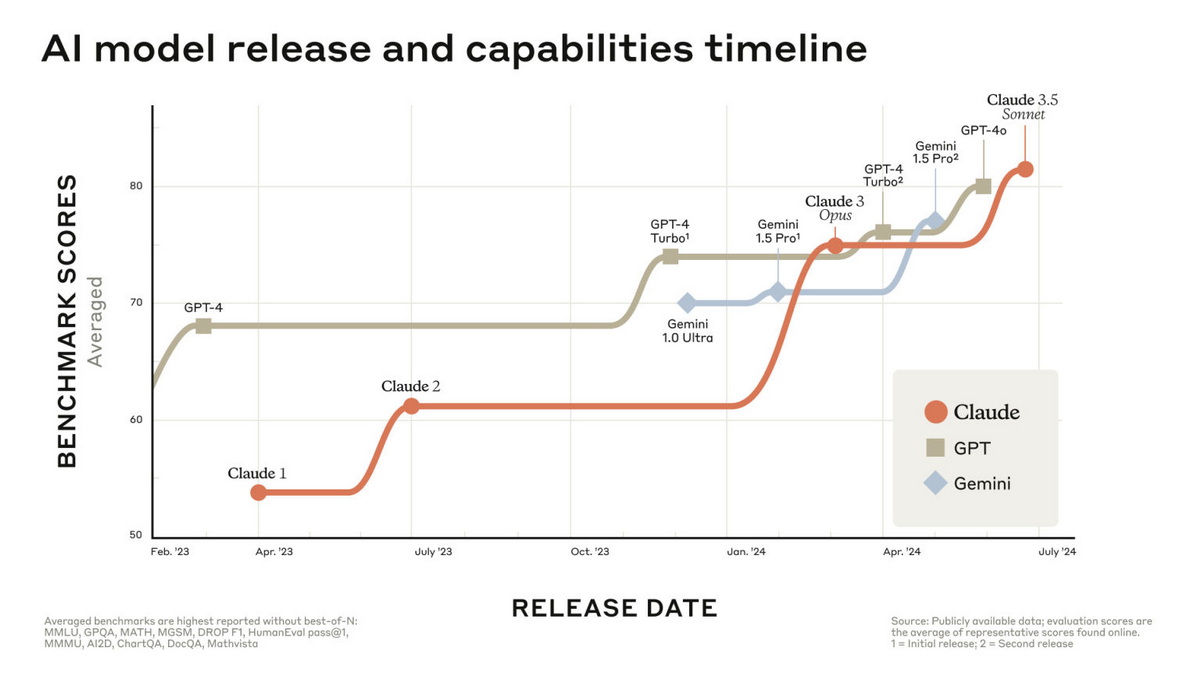
Таким образом, повторяется ситуация десятилетней давности на рынке смартфонов, когда устройства на Android, долгое время уступавшие продукции Apple во всем кроме цены, в конце концов смогли догнать лидера по большинству характеристик при такой же или более низкой стоимости и заняли (по данным StatCounter за май 2024 года) более 70% рынка. В Anthropic делают ставку на то, что спрос на генеративный ИИ будет расти, а пользователи и бизнесы начнут искать способы снижать издержки. Одним из них может стать переход на модели с более низкими расценками на доступ.
Anthropic основали в 2021 году семеро специалистов из OpenAI, недовольных углублявшимся с 2019 года партнерством компании с Microsoft и отходом от провозглашавшихся ею ранее ценностей создания ИИ на благо человечества. Возглавил компанию Дарио Амодеи, в OpenAI занимавший пост вице-президента по исследованиям, вместе с ним ушли в Anthropic его сестра Даниела Амодеи, заняв в компании роль президента, и ведущий инженер разработки нейросетей GPT Том Браун. К настоящему моменту компания привлекла $7,6 млрд, причем $7,3 из них — в 2023-м. Все доли инвесторов миноритарные, и они не получили представителей в совете директоров. Последние данные о стоимости всей Anthropic датированы декабрем 2023-го, тогда компанию оценивали в рамках переговорах об очередном раунде инвестиций в $18,4 млрд.
Компания не испытывает недостатка в ресурсах, большую часть которых предоставили в прошлом году Google и Amazon. Основной мотивацией IT-гигантов стало желание минимизировать риски технологического отставания от главного (и единственного крупного) партнера OpenAI, Microsoft. Хотя точная структура этих инвестиционных сделок не раскрывается, известно, что большая часть вышеупомянутых миллиардов — не живые деньги, а своего рода «серверный кредит», возможность использовать вычислительные мощности в дата-центрах для тренировки и работы своих нейросетей. При этом инвестиции уже приносят доход: Microsoft, Amazon и Google зарабатывают, продавая доступ к ИИ-моделям, работающим в облаке на их серверах. Аренда небольшого кластера может стоить от 20 долларов в час, более мощные могут обходиться заказчикам в 100 долларов в час и более.
Неплохо зарабатывают и сами ИИ-стартапы. OpenAI, как рассказал в июне сотрудникам гендиректор Сэм Альтман, сейчас генерирует деньги со скоростью $3,4 млрд в год, при том, что за весь прошлый год заработала около $1,6 млрд. Текущие заработки Anthropic оценить сложнее. В декабре 2023 года компания, по данным двух источников The Information, рассчитывала заработать за 2024 год $850 млн, а за три месяца до этого представители Anthropic обещали инвесторам в 2024-м $500 млн выручки. Насколько оптимистично компания смотрит в будущее сейчас, спустя полгода и после выпуска нескольких громких продуктов — неизвестно.
в канале MAX



