Семантика с ИИ до ставки: как настроить Директ, который продает, а не просто приводит трафик
Критика слепого следования ИИ-кластеризации: почему ИИ путает «купить» и «скачать бесплатно»
Зачем тратить 5 часов на сбор ключевых фраз для рекламной кампании, если достаточно прогнать всё через ИИ и получить готовую семантику за пару минут? Это можно сделать, но не всё так просто.
Нейросети помогают ускорить сбор тематических запросов и составить список из тысяч ключей за минуты. Но есть несколько проблем, с которыми можно столкнуться в процессе сбора.
Галлюцинации из-за отсутствия данных
У большинства простых и устаревших моделей есть главная цель: дать ответ пользователю, даже если для его подкрепления нет верифицированных данных. И если у ИИ нет достаточного доступа к информации, он начинает придумывать несуществующие или нерелевантные запросы на основе шаблонов.
Например, формулирует несуществующие long-tail запросы: «защита яндекс директ» → «охрана яндекс директ кликов», которых нет в реальной семантике.
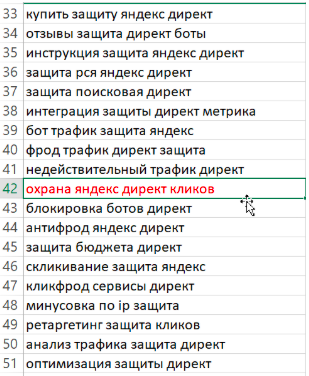
Размытый интент
Подобранная ключевая фраза для объявления не всегда выстреливает и увеличивает продажи. Почему? Потому что не соответствует интенту ЦА.
Нейросети, такие как ChatGPT, обучаются на публичных данных, куда списки семантических ядер не выкладываются в открытый доступ. В результате ИИ не имеет достаточной выборки реальной кластеризованной семантики → не может на ней обучиться → не может сгенерировать паттерн.
👉 Поэтому нейросеть не всегда может отличить коммерческие запросы, например «купить», от информационно-пиратских 🦜🏴☠️: «скачать бесплатно».
Кроме того, ИИ не учитывает реальные цели и намерения пользователя, который ищет определенный товар или услугу. Смешанный контекст запросов приводит к размытию интента и генерации нерелевантных ключей.
Например: «photoshop» → «купить photoshop», «скачать photoshop бесплатно», «урок по photoshop».
Ошибки кластеризации и каннибализация
Такая ошибка характерна не только машине — это и человеческий фактор тоже. Собрать ядро, а затем раздробить его так, что запросы между кластерами будут пересекаться и «съедать» друг друга.
В Яндекс Директе каннибализация приводит к самоконкуренции: когда две или более группы ваших рекламных объявлений (поиск и РСЯ, брендовые и общие, Мастер кампаний и «ручные» РК) конкурируют друг с другом, повышая ставки и съедая бюджет из-за досадной ошибки.
Например:
Игнорирование локальных особенностей и сезонности
Нейросети часто генерируют универсальные ключи без учета локальных особенностей. Так же, как и «поребрик» → «бордюр», в локальной выдаче по широкой стране нашей запросы ЦА могут варьироваться в зависимости от региона и других ситуаций.
Например: для «детейлинг авто» ИИ может выдать «детейлинг авто спб» или «детейлинг москва цены», но не учтет, что в Санкт-Петербурге, например, могут быть популярны запросы «детейлинг авто на Васильевском».
Сезонность тоже страдает: летом ИИ не предложит сделать упор на запрос «антикоррозийная обработка авто» с пиковыми запросами в августе-сентябре. Без данных из Wordstat это приведет к обеднению семантики и потере части аудитории.
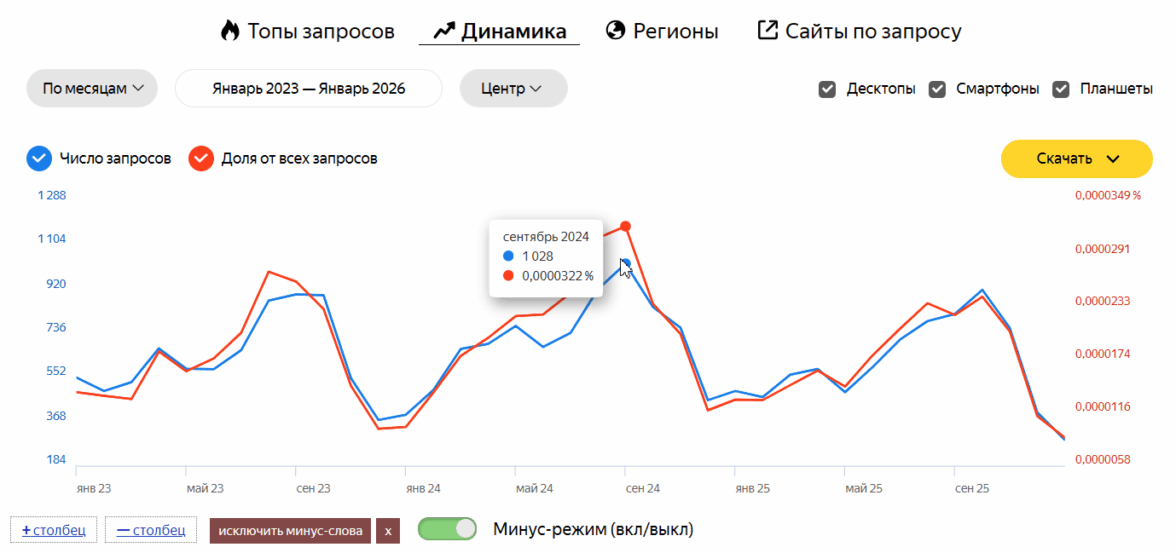
Отсутствие учета частотности и конкуренции
ИИ выдает тысячи ключей, но не ранжирует их по реальной частотности. Сгенерированный список может быть забит низкочастотными «хвостами» по типу «покрытие кузова керамикой плюсы и минусы», которые не окупаются, или высокочастотными монстрами по типу «мойка авто», где CPC зашкаливает.
Без интеграции с инструментами по сбору ключей — платными и бесплатными — нейросеть не покажет частотность и не предложит баланс между объемом трафика и бюджетом. Результат — перерасход на бесполезные запросы.
Зависимость от промпта и качество входных данных
Качество собранной семантики напрямую зависит от вашего промпта к нейросети. Если ввести «собери ключи по детейлингу», ИИ выдаст сборную солянку.
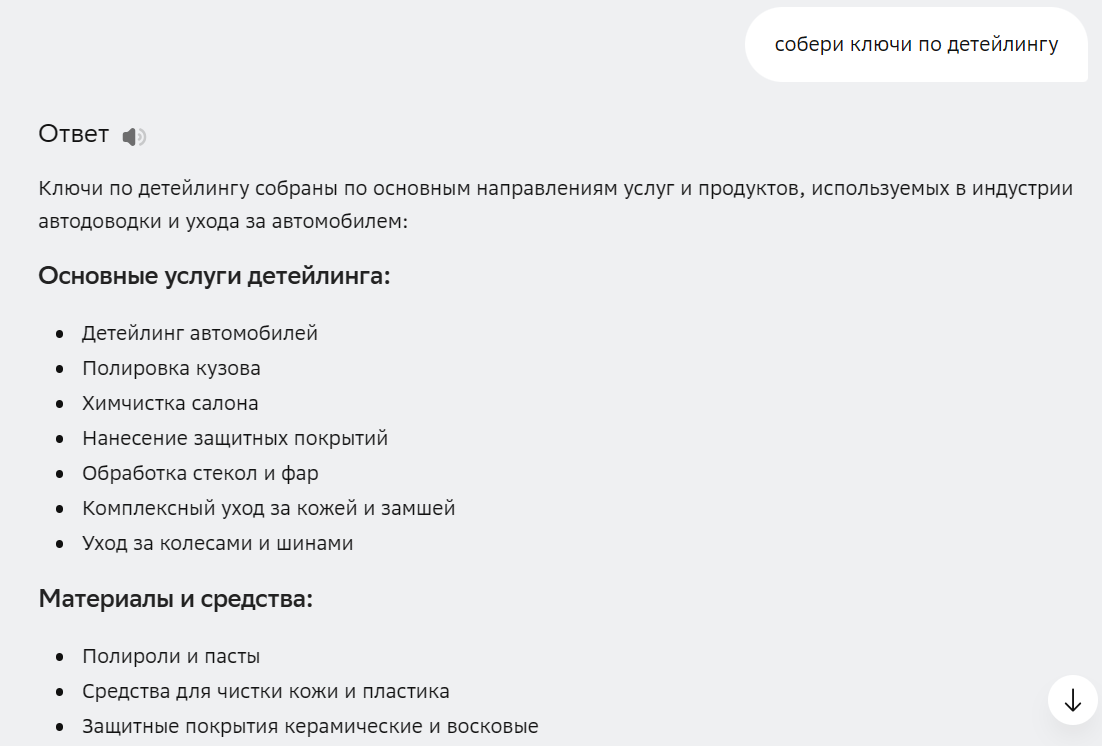
А если уточнить «коммерческие запросы детейлинг авто Москва, минус слова: бесплатно, торрент», то результат сильно улучшится.
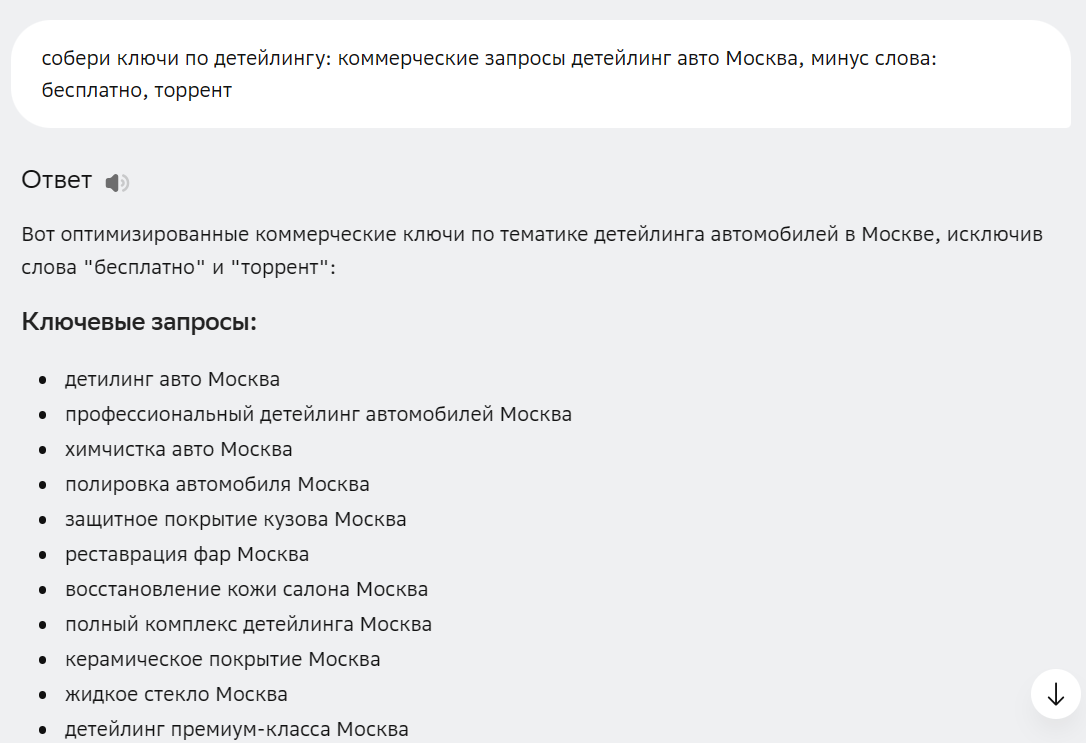
Кроме того, модели, такие как GPT-4o или Gemini, ограничены обучением на данных до 2023–2024 гг., так что свежие тренды они могут упустить.
Как «укротить» нейросеть и избежать ошибок при сборе ключевых фраз
► Прописывайте четкий промпт, но не указывайте в одном запросе слишком много подробностей.► Запрашивайте выполнение действий последовательно.► Если происходит смешение интентов (купить/скачать бесплатно), добавляйте в промпт минус-слова, кластеризуйте по топам из выдачи, задавайте сбор списка по маскам или маркерным запросам.► Для отсечения нецелевых, низкочастотных ключей используйте комбо-связки: ИИ + Key Collector, SpyWords или др.► Если в список попадают нерелевантные хвосты, выполните ручную фильтрацию + проанализируйте конкурентов.► Прибегайте к методу двойной фильтрации (нейросеть + Wordstat + подсказки + инструменты).
Не игнорируйте минус-слова и уточнения, чтобы нейросеть чётче понимала вас. Приводите примеры, но с осторожностью — ИИ может начать использовать как паттерн на «всё и сразу», а это прямой путь к галлюцинациям.
Метод «двойной фильтрации»: как соединить нейросеть (ChatGPT, YandexGPT, другие) и ручной анализ
Каким бы удобным ни был искусственный интеллект для сбора семантики, без ручной сборки ключевых фраз не обойтись. Вот что нужно делать:
Шаг 1. Используем ИИ как черновик
Прописываем промпт. Например: Собери 100 ключевых запросов для «детейлинг авто Москва», только коммерческие интенты. Учитывай сезонность.
Или вместо этого запроса указываем конкретный сайт и просим его проанализировать и на основе этого собрать ключевые маски или маркеры по группам. Можно комбинировать с промптом выше.

Шаг 2. Чистим ключи от откровенного «мусора»
Даже с настроенным промптом в подобранный список могут попадать «засланные казачки»: смена слова на синоним («быстрая» → «экспресс»), галлюцинация и заимствования «мобильный детейлинг февраль» и др.
Нейросеть не показывает частотность ключей. Поэтому всё собранное придется перебирать ручками. Для этого используем Wordstat или другой инструмент, которым вы привыкли пользоваться — только те запросы, которые нас больше всего интересуют.
Альтернатива: поступаем проще, но дольше — на первом шаге формируем запросы по маскам последовательно.
Шаг 3. Дополняем семантику подсказками
В процессе анализа Wordstat можно еще донабрать некоторые запросы. Подсказки в поисковой строке и под результатами поиска в выдаче также позволят дополнить этот список.
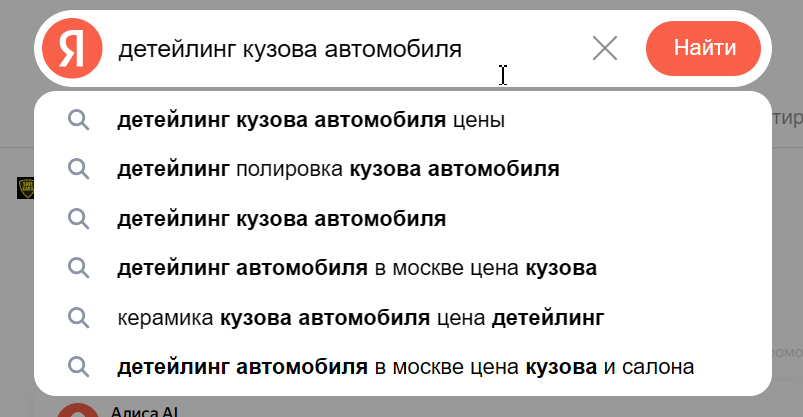
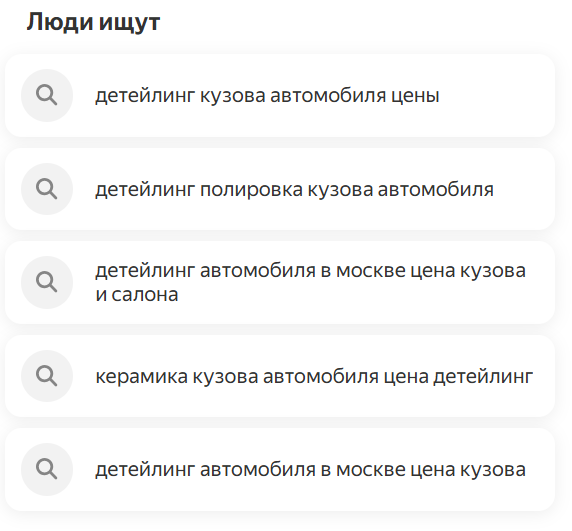
Нейросети помогают находить новые маски ключей, которые еще не используются, в том числе синонимы, LSI-, околотематические запросы. В общем, ИИ подскажет идеи по формированию семантики.
Шаг 4. Используем ИИ для кластеризации (группировки)
Старайтесь учитывать, что мы кластеризуем запросы под группы рекламных объявлений в Яндекс Директ. Что важно сделать:
-
прописать четкий промпт на основе очищенных данных. Например: Кластеризуй эти запросы под группы объявлений в Яндекс Директе. [дополнительные директивы с вашими условиями];
-
обязательно указать, для чего это нужно сделать (☝ группы объявлений в Директе);
-
попросить убрать дубли, информационные запросы и др.
Ваша задача — последовательно выуживать информацию из ИИ и просить выполнять нужные вам действия. Так нейросеть: 1) обучается на ваших данных, 2) использует контекст диалога, на который может опираться.
👉 Автоматическая обработка семантического ядра обязательно должна быть проверена человеком, так как алгоритмы подходят формально и могут упустить нюансы живого восприятия.
Собранные кластеры помогут: 1) распределить ключи на «горячие» (поиск) и «холодные» (РСЯ), 2) определить стратегии ставок: высокие — для коммерции, низкие — для бренда.
Шаг 5. Анализируем конкурентов
Для этого можно использовать простую выдачу — смотрим на рекламу в поиске и на официальный сайт в органике. Или используем инструменты-анализаторы: SpyWords, KeySo.
Смотрим: куда ведут ссылки, на какие посадочные, под какие ключи, какие триггеры используются и т. д. Дополняем и корректируем.
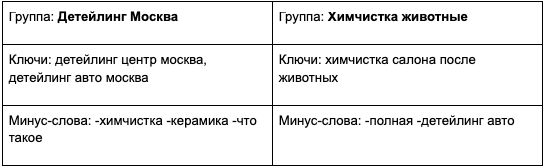
Шаг 6. Исключаем каннибализацию и прописываем минуса
Шаг 7. Настройка кампании в Директе
Создавайте одну группу объявлений на кластер с несколькими объявлениями в каждой. Добавляйте минус-слова и минусуйте фразы для исключения возможной каннибализации. Для настройки рекламы в РСЯ подробная кластеризация не потребуется — достаточно будет собрать маски с ВЧ-/СЧ-запросами, без микрочастотных и long-tail.
Но! Не делите семантику на множество рекламных кампаний. Лучше структурировать кампании так, чтобы одна кампания соответствовала одному продукту, а одна группа объявлений — одному свойству продукта (маске ключевого слова).
Интеграция UTM-меток и сквозной аналитики для проверки трафика и отслеживания ROI
Регулярно отслеживайте динамику трафика и конверсий в кампании по ключам и другим параметрам. Важно выполнить предварительную подготовку:
-
На этапе настройки рекламной кампании прописать UTM-метки с динамическими параметрами.
-
Подключить сквозную аналитику (если требуется) к Директу и Метрике.
-
Учитывать уровень фрода в нише для блокировки недействительного трафика.
UTM
На этапе настройки рекламной кампании обязательно укажите UTM-метки.
Например, utm_campaign:
-
Поиск: utm_campaign=poisk_deteyling
-
РСЯ: utm_campaign=rsya_himchistka
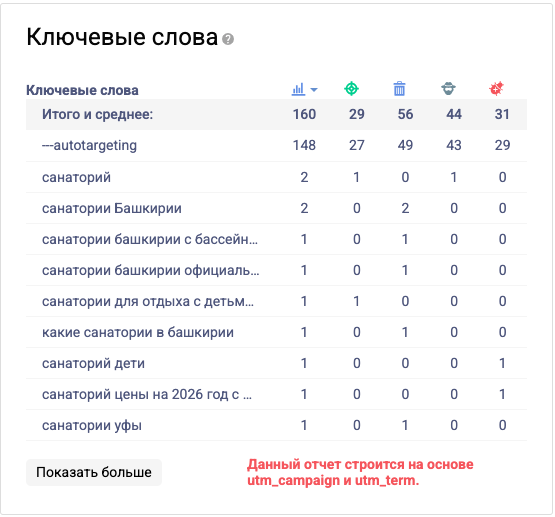
Чтобы отслеживать эффективность каждого ключа — utm_term:
-
utm_term={keyword} — система автоматически будет подставлять ключевое слово, по которому произошел показ или переход.
Сквозная аналитика
Сквозная аналитика поможет собирать данные от клика по объявлению до финальной конверсии (лид, продажа) и связывать ключи из Директа с реальным доходом. Используйте статистику, чтобы понять, какие запросы окупаются, а какие сливают бюджет.
Как сквозная аналитика помогает отслеживать ключи:
-
Поиск по utm_term → группировка конверсий по точному ключу;
-
Связь с коллтрекингом → звонки привязываются к utm_term=детейлинг кузова;
-
Подсчитать ROI: (Доход от ключей — Стоимость кликов) / Стоимость кликов × 100%. Можно использовать следующую формулу для таблицы:
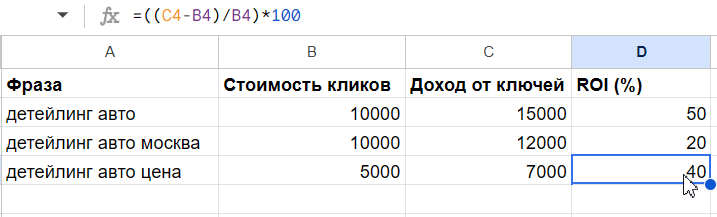
Пример оценки эффективности ключей:
-
poisk_deteyling – детейлинг центр москва → 50 кликов → 5 лидов → 150 000 ₽ выручки;
-
rsya_himchistka – химчистка салона после животных → 5 кликов → 0 лидов → 0 ₽
Также можно отслеживать LTV (ценность клиента) по отдельным ключам. Анализ поможет отследить маржинальные ключи и изменить ставки для наиболее эффективных. Например, повышайте на ключи, у которых LTV в сравнении с CAC (стоимость привлечения по ключу = стоимость кликов / лиды) больше 3, снижайте или отключайте, если LTV меньше CAC. Используйте для ретаргетинга и масштабирования.
Антифрод
Помним про фрод в рекламных кампаниях: на поиске — скликивание запросов конкурентами для вытеснения из платной выдачи; в РСЯ — накрутка кликов и конверсий владельцами площадок (особенно в мобильных приложениях и dsp-сетях).
Если по определённым ключевым фразам идёт большой объём недействительного трафика, то такие ключи можно временно отключить.
Фродовые признаки:
-
высокий показатель отказов (50-100%);
-
короткие сессии (<10 секунд);
-
низкая глубина просмотров;
-
низкий % до целевых действий;
-
для РСЯ: низкая стоимость клика + массированные отказы и нулевые конверсии;
-
подозрительные источники визитов, гео и др.
Фразы отслеживаем через сквозную аналитику, Метрику и Директ → отключаем сами фразы/площадки/аудитории — зависит от ваших приоритетов.
Можно подключить автоматическую проверку фраз и отключение ключевых слов через систему антифрода.
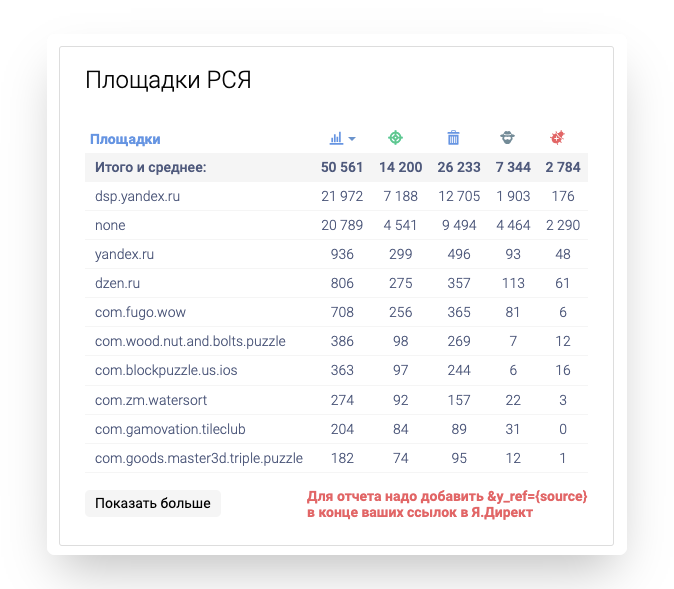
Предпоследняя и последняя колонки — боты.
Вывод
ИИ — это отличный ускоритель сборки ключей на реактивно-цифровой тяге, но он не заменяет участие человека и последующую ручную кластеризацию с донастройкой под бизнес, бренд, гео и цель продвижения. Эффективность рекламных кампаний вырастет только в связке: живой ум + автоматизация.




