Google забыл про сайт: пошаговая инструкция по спасению
Проверили сайт под микроскопом
Автор: SEO-специалист Webit Ирина Сергеенко.
Индексация — это процесс, при котором поисковая система заносит страницы сайта в свою базу. Только после этого страницы могут появляться в поисковой выдаче. Если страница не проиндексирована — для Google ее как будто не существует. А теперь представьте, что из индекса выпадают ВСЕ страницы сайта. Именно с такой критической ситуацией мы столкнулись, работая над поисковым продвижением сайта образовательной платформы одного из крупнейших производителей алюминия. Разбираемся, почему это произошло, как восстановили видимость сайта и какие выводы сделали.

Полное обнуление в поиске
С середины марта 2025 года Google начал исключать из индекса страницы сайта, реализованного с помощью JS-фреймворка React.
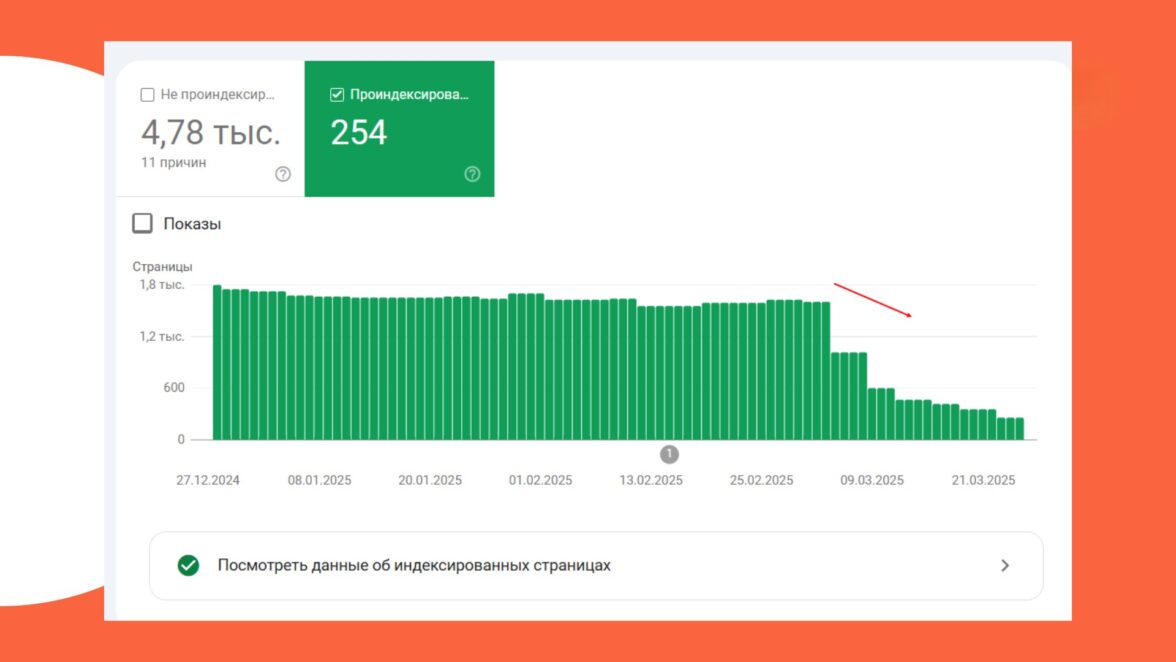
Уже к началу апреля ни одна страница сайта, включая главную, не индексировалась в Google.
Отметим, что проблема затронула только Google, индексация в Яндексе осуществлялась без нареканий. Вот что показал технический аудит:
-
все страницы открываются нормально — сервер отвечает кодом 200 OK, то есть страницы доступны и загружаются без ошибок;
-
Google видит контент — через Search Console выяснили, что страницы доступны и отображаются корректно;
-
есть серверный рендеринг (SSR) — поисковики получают полные HTML-версии страниц, а не только «пустую оболочку» без контента;
-
правильные canonical-ссылки — на всех страницах указано, какая версия считается основной;
-
нет запретов на индексацию — в мета-тегах robots не стоит запрет на сканирование;
-
файл robots.txt не мешает — он запрещает только дублирующие страницы с параметрами, а не основные.
То есть все страницы были технически доступны, но при этом Google их не индексировал.
Проверили сайт под микроскопом
Мы решили провести детальную проверку и выдвинули несколько предположений, почему сайт не индексируется в Google.
-
Ответ сервера 403 или другой блокирующий код.
Предположение: если сервер возвращает код 403 Forbidden, Googlebot не сможет просканировать страницу.
Проверка: страницы доступны для всех поисковых ботов, включая Googlebot, и возвращают код ответа 200 OK.
Вывод: серверные ответы корректны, блокировки по статус-кодам отсутствуют. -
Защита на стороне сервера (WAF или антибот-защита).
Предположение: некоторые серверы или CDN (например, Cloudflare) могут блокировать автоматических ботов (включая Googlebot), если они подозрительно выглядят или не проходят проверку. Особенно часто это делают веб-файрволы (WAF), если сайт защищен.
Проверка: на сайте действительно установлена защита, ограничивающая доступ из некоторых стран. Однако обращения от Googlebot из любых регионов успешно проходят, блокировки не зафиксированы.
Вывод: защитные механизмы не препятствуют доступу Googlebot к сайту. -
Некорректный пустой .
Предположение: на страницах сайта присутствует без корректного значения атрибута content. В некоторых случаях поисковые системы могут интерпретировать некорректные или пустые значения как noindex.
В нашем случае было зафиксировано:{«name”:”robots”,”content”:”$undefined”}
Такое значение может быть интерпретировано Googlebot как отсутствие инструкции либо как запрет на индексацию.
Проверка: протестировано, мета теги robots устранены, значения content=»$undefined” убраны.
Вывод: в этом случае наличие content=”$undefined» в метатеге robots не оказывает влияния на сканирование и индексацию со стороны Googlebot. -
Избыточный вес страниц.
Предположение: страницы (например, главная) могли стать слишком «тяжелыми» за счет большого объема CSS, JavaScript и неоптимизированных изображений. Это потенциально влияет на рендеринг: Googlebot имеет ограничения по ресурсам и времени обработки, и при перегрузке скриптами он может не успевать добраться до основного HTML-контента, особенно на React-проектах.
Также учитывалась вероятность несовместимости с обновленной версией React, которая могла случайно добавить лишний код или нарушить SSR.
Проверка: структура бандла не изменилась, новые библиотеки не добавлялись, размер CSS и JS файлов оставался стабильным. Вес страниц не имел значительного увеличения.
Вывод: производительность и вес страниц не изменились, проблем с рендерингом и индексацией по этой причине не выявлено.
Скрытая ошибка, которую мы все-таки нашли
Основную причину выпадения страниц из индекса мы обнаружили спустя пару недель. Кто же был «виновником» торжества?
Источником проблемы была конфигурация файла robots.txt и особенности реализации сайта на React.
Хотя сайт был настроен на серверный рендеринг (SSR), Googlebot по какой-то причине не использовал готовую HTML-версию страниц для индексации. Вместо этого он пытался загружать и обрабатывать контент через клиентский рендеринг — то есть «собирать» страницу прямо в браузере. Для этого Googlebot обращался к URL с query-параметрами, главным из которых был «? rsc=» — именно через него подгружался основной контент. Но эти параметры были запрещены в файле robots.txt, поэтому бот не мог получить доступ к нужным данным.
Хотя Google и трактует robots.txt как рекомендацию, в этом случае он воспринял запрет буквально (как прямое указание к действию!) и полностью исключил такие страницы из индексации.
Более того, Googlebot также обращался к поддомену с API (api.site.ru), который отдает данные в формате JSON для клиентского рендеринга. Но и там файл robots.txt копировал правила с основного сайта, включая запреты на параметры — в итоге бот не мог получить даже исходные данные.
При этом все страницы при проверке в Search Console были полностью доступны боту и имели весь необходимый контент.
Дополнительно были заблокированы параметры «? url=» и «? search=», которые Googlebot тоже использует для загрузки контента. Все вместе это делало ключевую информацию недоступной для индексации.
Починили все: от robots.txt до поддоменов
Чтобы вернуть страницы в индекс, мы пересмотрели правила в файле robots.txt на основном домене — убрали запреты на ключевые query-параметры (rsc, url и другие), через которые подгружается важный контент.
Такие же правки внесли и в robots.txt поддомена api.site.ru, поскольку Googlebot обращался к нему за данными при попытке собрать страницу через клиентский рендеринг.
После этих изменений Google наконец получил доступ ко всем необходимым ресурсам — страницы начали возвращаться в индекс, а видимость и трафик — расти.
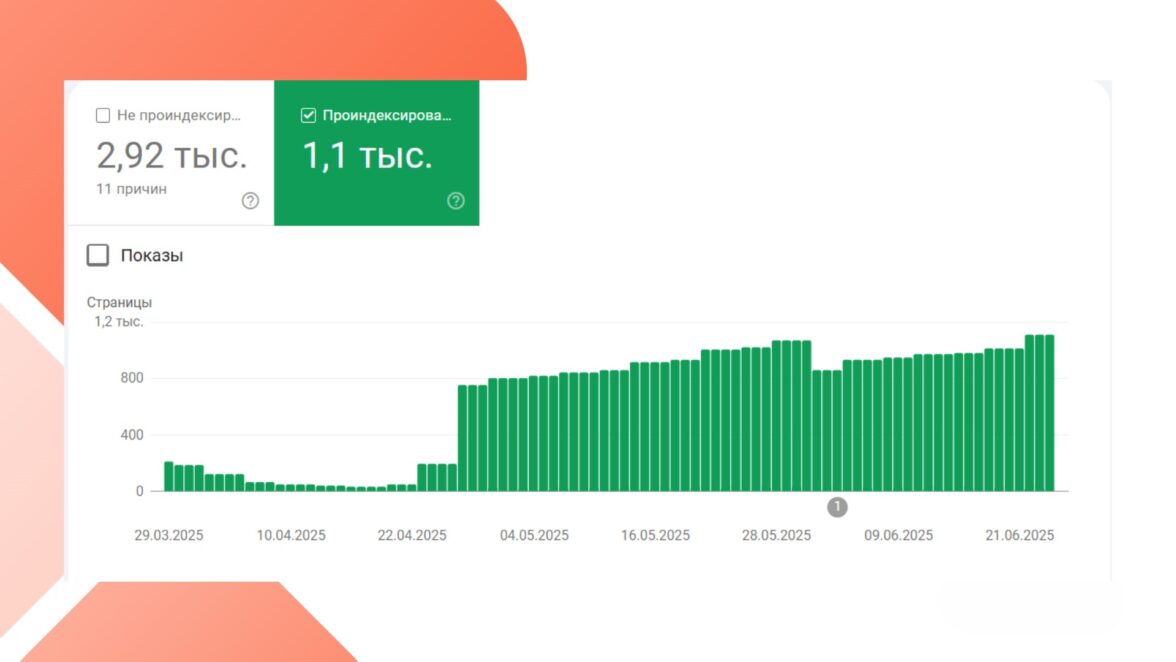
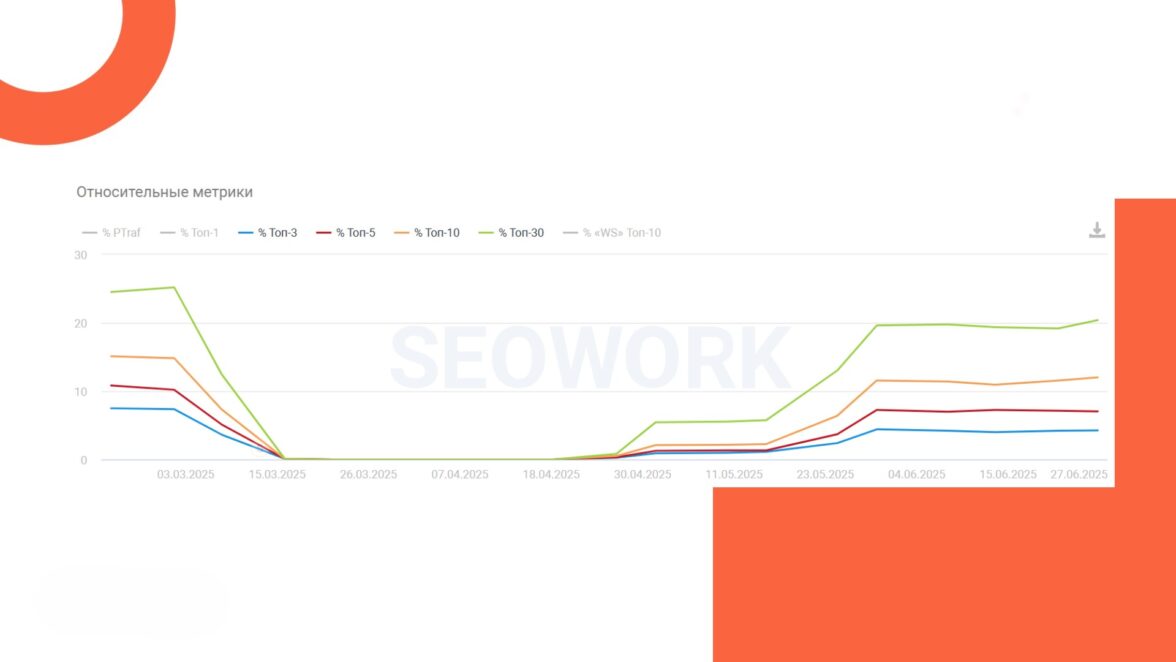
Инсайты после кризиса индексации
Если Google внезапно исключает страницы из индекса при видимой технической доступности (особенно на сайтах, реализованных на фреймворке):
-
проверьте robots.txt — возможно, в нем случайно заблокированы query-параметры или динамические URL, через которые подгружается контент;
-
не забудьте про поддомены и API — Googlebot может ходить за данными не только на основной сайт, но и на сторонние сервисы. Убедитесь, что доступ к ним не ограничен;
-
используйте Google Search Console — в разделе «Просмотр страницы» → «Заблокированные ресурсы» видно, что именно мешает боту получить нужный контент.
Чем сложнее сайт, тем внимательнее нужно подходить к деталям. В нашем случае грамотная диагностика и точечные правки вернули сайт в индекс и восстановили трафик. Шаг за шагом и без паники.