AI-агенты и мультиагентные системы: реальное внедрение вместо хайпа
От LLM-приложений к AI-агентам
Развитие приложений на базе больших языковых моделей прошло несколько стадий. Сначала это была классическая генерация текста или изображений без дополнительных функций. Затем появились диалоговые системы с памятью, которые уже могли вести полноценный разговор и использоваться как первая линия поддержки. Главный тренд последних лет — агентские системы. Агент отличается от простого чат-бота тем, что способен сам принимать решения: он запрашивает данные, вызывает внешние сервисы и взаимодействует с корпоративными системами.
Для бизнеса агенты стали прежде всего инструментом экономии и оптимизации. Если генеративные модели помогали «зарабатывать», то агенты чаще решают задачи «про сэкономить».
Где AI-агенты приносят наибольшую пользу
Наибольший эффект агентские решения показывают в трёх направлениях. Первое — оркестрация сложных процессов. Здесь агенты интегрируются в корпоративные чаты, собирают и резюмируют договорённости, подводят итоги видеозвонков или помогают в DevOps-задачах, например через Telegram-бота. Второе направление — повышение продуктивности сотрудников. Ассистенты для новичков позволяют быстрее разбираться в сложных системах.
В корпоративных сценариях особенно эффективны мультиагентные системы, где отдельные агенты специализируются: одни собирают данные, другие анализируют, третьи взаимодействуют с пользователями.
Кейс
Так, в нашем кейсе для промышленной компании агент был встроен в систему «КОМПАС-3D» и помогал инженерам проверять схемы и задавать вопросы по платформе. На базе того же решения был создан интеллектуальный ассистент для службы поддержки пользователей. Он автоматически обрабатывал входящие запросы: понимал тематику и уровень сложности вопроса, искал ответ в документации и базе знаний через LLM и семантический поиск, отвечал пользователю, если находил релевантный материал, или же эскалировал нестандартные случаи в нужную рабочую группу. Ассистент постепенно обучался на новых кейсах и расширял базу знаний, что позволяло улучшать качество работы поддержки. В результате время до первого ответа сократилось с 1–2 часов до <2 минут, доля запросов, решённых на первом уровне, выросла с 20-30% до 60-80%, а время передачи сложных запросов на следующий уровень поддержки снизилось с 4 часов до <1 часа.
И третье направление — снижение барьеров. Речь идёт о задачах, когда в компании используется старая система, и мы исключаем необходимость онбординга пользователя. Вместо этого формируется автоматизация: например, создание платёжного поручения и его запись напрямую в 1С, без необходимости открывать программу и вручную заводить платёжку.
Старт проекта: от ожиданий к метрикам
Когда бизнес приходит с запросом на создание агента, очень часто ожидания оказываются завышенными. Руководители посмотрели интервью Anthropic или OpenAI и уверены, что нашли универсальное решение всех проблем: «давайте сделаем агента, он должен уметь всё и работать с идеальной точностью». На практике всё иначе. Важно прежде всего определить KPI, которые будут отражать успех внедрения именно с точки зрения бизнеса. Эти KPI затем переводятся в конкретные метрики. В классическом машинном обучении ключевыми показателями считаются точность и полнота, и они действительно должны быть высокими. Но в случае с агентами подход иной. Примером может служить Character AI, выпустивший продукт с цифровыми аватарами. Система далеко не всегда работала корректно, но эта неточность скорее стала мемом, чем проблемой, и не повлияла на популярность сервиса. Совсем другая ситуация в медицине, где даже один процент ошибки на выборке в тысячу пользователей способен привести к серьёзным последствиям и репутационным потерям. Поэтому при запуске агентских проектов важно честно определить, какие именно метрики действительно критичны в данном контексте.
И здесь возникает ещё один принципиальный вопрос:, а действительно ли нам нужен агент? До нынешнего хайпа многие были уверены, что определённые задачи невозможно решить иначе, кроме как через человеческий фактор. Теперь, когда появилась генеративная ИИ-технология, возникает соблазн использовать её везде. Но разработчики должны трезво оценивать, подходит ли она для конкретной задачи. Агент далеко не всегда является оптимальным решением. Например, для распознавания рукописного текста куда эффективнее применять классический Computer Vision подход: подключать OCR и обучать модель классическим решениям. Это даст более точный результат, обойдётся дешевле в эксплуатации и будет куда практичнее для бизнеса.
Данные как фундамент агентских решений
Если мы всё же решили, что агент нужен, то начинаем работу с данными. На этом этапе необходимо проанализировать, какие именно данные есть в распоряжении компании, будет ли обеспечен к ним доступ и содержат ли они персональную информацию. Иногда требуется собирать данные из внешних источников, например парсить их из Telegram-каналов, а в других случаях — проводить предварительную обработку, как это часто бывает с таблицами. Такой анализ позволяет оценить объём предстоящей работы, понять, сколько ресурсов потребуется, и заранее просчитать стоимость всего решения.
Наряду с этим нужно учитывать юридические и инфраструктурные ограничения. Здесь вступает в силу законодательство о персональных данных, которое накладывает требования к хранению и обработке информации. Также многое зависит от специфики заказчика: для компаний оборонного сектора важны высокий уровень секретности. Все эти нюансы необходимо учитывать ещё на стадии планирования, чтобы агентская система изначально проектировалась в соответствии с правовыми и техническими рамками.
Кейс
Компания, работающая на рынке аренды жилья, обратилась с задачей автоматизировать процесс суммаризации отзывов. Основная сложность заключалась в том, что использовать персональные данные было нельзя — вся информация бралась только из открытых источников. Кроме того, у клиента не было собственной инфраструктуры на GPU, поэтому мы приняли решение работать через API. В процессе реализации мы добавили дополнительную метрику, отвечающую за грамматическую точность предложений. Это оказалось критически важно: зарубежные и особенно китайские аналоги часто дают неверные формулировки, а клиенту требовался лаконичный и грамотный текст. Такая метрика позволила обеспечить качество генерации и сделать итоговые отзывы не только автоматизированными, но и стилистически аккуратными.
Выбор подхода к реализации: от no-code до программного кода
Первый подход — использование no-code и low-code инструментов, которые позволяют быстро создавать прототипы и проверять гипотезы. Они интегрируются через сервисы вроде Albato, который работает с более чем шестьюстами приложениями в России, или n8n, который особенно хорошо подходит для оркестрации процессов и связки LLM с бизнес-логикой. Для визуальной сборки пайплайнов и быстрой проверки идей используются Langflow и OSMI AI.
OSMI AI — это отечественная платформа для создания корпоративных high-load решений, рассчитанных на колоссальную нагрузку на вычислительные мощности, память, LLM-инфраструктуру и API-интеграции. Она позволяет строить рабочие сценарии без кода и наглядно тестировать разные варианты. Такой подход экономит ресурсы команды: не нужны дорогие специалисты и долгие циклы согласования, достаточно быстро проверить ценность гипотезы. Архитектура мультиагентных систем в OSMI AI строится на принципе оркестрации: агенты распределяют задачи между собой, обращаются к базе знаний и внешним API.
Но есть и второй путь — классическая разработка. В этом случае команды используют Python и связки вроде LangChain или LangGraph, которые дают полную гибкость, но требуют более высокого уровня подготовки и сложного входа. Часто поверх этих решений создаются собственные надстройки, позволяющие адаптировать фреймворки под конкретные бизнес-задачи. Такой подход выгоден для зрелых команд и сложных продуктов, которые выходят за рамки прототипа. Характерный пример — Т-Банк: сначала команда пыталась разработать собственный аналог LangChain, но затем отказалась от этой идеи и перешла к созданию обёрток вокруг готового фреймворка.
Плюс, независимо от выбранного подхода, необходимо учитывать, какую модель планируется использовать и в каких условиях она будет работать. Здесь вступают в силу нюансы лицензирования open source-библиотек и требования к стеку технологий. Например, если компания намерена регистрировать решение как интеллектуальную собственность и включать его в реестр Минцифры, важно заранее понимать, какие компоненты допустимы. Например, Redis Enterprise для этого не подойдёт, тогда как PostgreSQL официально разрешён и не вызовет проблем.
Построение системы
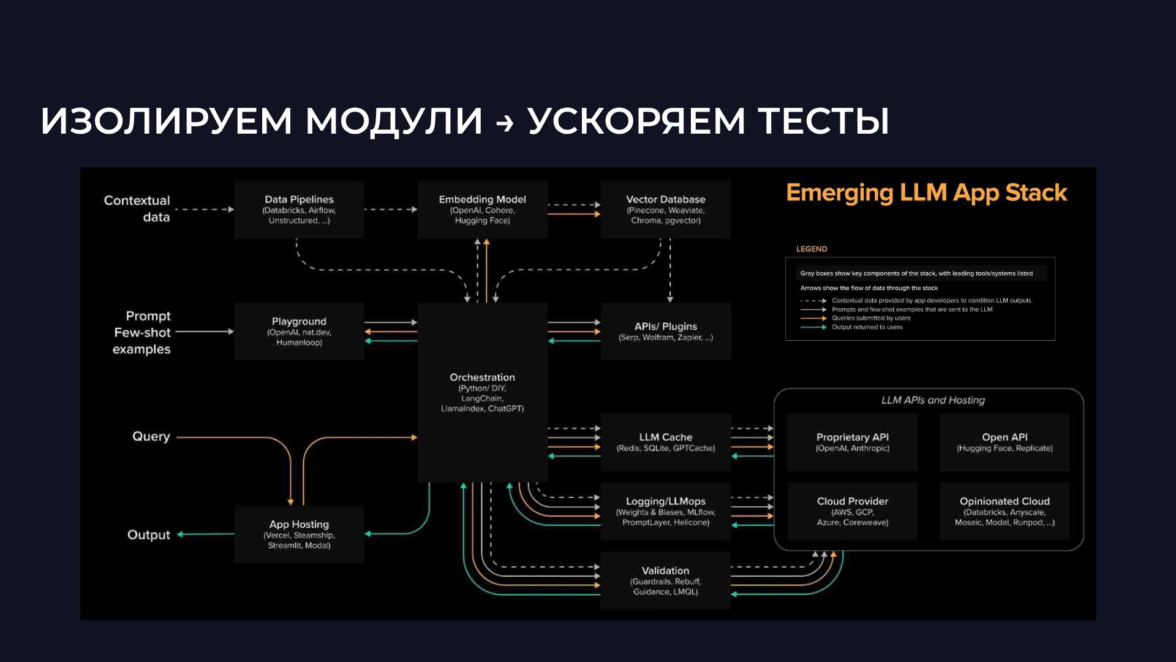
На схеме представлена целостная схема системы, которую мы получаем в результате. Она уже написана на коде, работает с высоким числом RPS и строится как модульная архитектура, что позволяет ускорять тестирование и масштабирование
Верхний уровень занимает RAG Pipeline— база знаний, которую агент использует для генерации ответов. Она вынесена в отдельный модуль. Ниже располагается уровень оркестрации — это может быть LangChain или low-code-приложение, отвечающее за распределение и последовательную обработку запросов между модулями. Следующий слой — работа с LLM. Здесь к простой отправке запроса через API добавляется валидация, которая модерирует контент и маскирует персональные данные. Дополнительно используется кэш LLM: часто повторяющиеся запросы фиксируются и обрабатываются напрямую, без лишних вычислительных затрат.
На уровне работы с самой LLM система может подключаться либо к стороннему провайдеру, либо к внутренней корпоративной модели. А в отдельный модуль выносится интерфейс приложения: это может быть Telegram-бот, внутренний корпоративный портал или даже простой виджет на сайте. Таким образом формируется иерархия агентов.
Наш опыт
В OSMI AI архитектура мультиагентных систем реализуется через иерархию уровней: оркестрация, взаимодействие агентов, контроль качества ответов. В качестве примера — проект для B2B-портала, где мы создавали мультиагентную систему, полностью интегрированную в e-commerce. Он позволял пользователям искать товары, добавлять их в корзину, а встроенный модуль авторизации определял, кто именно делает запрос. Помимо этого ассистент формировал отчёты о статусах заказов. Вся функциональность была разделена на отдельные модули, и именно итеративный подход с регулярными релизами позволил выстраивать систему шаг за шагом.Над проектом работали порядка 12 команд. Начали с самого простого — с поиска по сайту. Первоначально он работал на алгоритме Левенштейна и часто ошибался, но затем был заменён на более сложный семантический поиск. Мы постепенно улучшали его, ориентируясь на обратную связь пользователей. Это было особенно важно, поскольку аудитория портала состояла из инженеров, которые формулировали запросы в профессиональном сленге и часто оперировали крайне специфическими параметрами. Сам интернет-магазин содержал около 5 млн товаров — от транзисторов до резисторов и компонентов с характеристиками вроде «40 Ом» или «420 нанометров». Для того чтобы система научилась корректно работать с такими запросами, мы последовательно собирали данные и дорабатывали функционал. В итоге точность поиска вышла на высокий уровень, позволяющий ускорить процесс закупок и снизить затраты на импорт.
На чём можно сэкономить?
Одним из ключевых факторов стоимости проекта становится выбор модели. На практике мы всегда проводим отдельный анализ, сравнивая разные варианты. Например, в кейсе в саммаризацией отзывов, который уже упоминали выше, мы рассматривали два пути: использовать API или развернуть модель в собственной инфраструктуре с закупкой оборудования. Разница оказалась очевидной — API вышло в разы дешевле.
Дополнительную экономию можно получить за счёт особенностей самих моделей.
У одних есть кэш промтов, тот что снижает количество вычислений и позволяет экономить ресурсы, у других — нет.
У некоторых открыто опубликованы данные о скорости инференса, у российских аналогов такой информации почти нет.
Поэтому часто мы используем комбинированный подход: простые задачи с большим количеством токенов решаются лёгкой моделью, а сложные сценарии перекладываются на более тяжёлую. В случае с саммаризацией скорость инференса не критична, поэтому комбинация нескольких моделей позволяет снизить расходы без потери качества.
Следующий шаг — быстрый прототип. На этом этапе особенно удобны low-code-решения: они позволяют быстро собрать систему, прогнать её на реальном трафике, проверить метрики точности и стоимости и понять, совпадают ли ожидания с фактическим результатом. Весь процесс логируется, и эти данные затем используются для доработки и перевода решения в код.
Экономия проявляется и в архитектурных решениях. Так, в одном проекте для производителя джинсов мы разрабатывали онбординг-ассистента, который помогал новым сотрудникам проходить обучение и тесты. Для этого пришлось создать интеграционный модуль, связывающий систему с 1С: по номеру телефона определялось, какой сотрудник делает запрос. А вот в другом проекте, e-commerce-портале, авторизация была решена проще: виджет на сайте по cookie подтягивал JWT-токен и система сразу понимала, кто пользователь. За счёт этого отдельный интеграционный модуль не понадобился, что позволило заметно сократить затраты на разработку.
Онбординг
Тут перед нами задача динамически обновлять данные из базы, что фактически превращается в отдельный мини-проект. В нашем кейсе мы начали с интеграционного слоя для сбора информации из Motivity, где данные находились в разрозненном виде: часть в jpeg, часть в pdf, таблицах и простом тексте. Чтобы привести всё к единому формату, применяли разные методы: где-то использовали классические алгоритмы, а для задач OCR разворачивали Qwen 2.5–7B. После перевода всего массива в текст мы разбивали его на смысловые блоки, проводили предобработку и формировали чанки с помощью LLM. Далее данные переводились в эмбеддинги с сохранением источника — фиксировались доменные имена и файлы, из которых они были извлечены. Результат помещался во векторное хранилище с разделением на коллекции, что позволило автоматизировать дальнейшую работу.
Отдельным модулем подключалась validation-логика: antifraud-проверки и маскировка персональных данных для соблюдения требований ИБ. Для этого использовали небольшие классификаторы. В MLOps применялся Langfuse, который можно развернуть в контуре без лицензии — его ограниченного функционала вполне хватало. Дополнительно мы интегрировали фреймворк RAGAS для формализации и автоматизации вопросо-ответной системы: это позволяло чат-боту постепенно дополнять базу знаний.
Для хранения контекста подключались различные механики: векторная память, саммаризация диалогов, ограничение количества сообщений и кэширование запросов. Параллельно использовалась структурная база данных, где агент выполнял Text-to-SQL запросы и понимал, когда отправить уведомления или как получить ключи для дальнейших операций.
Дальше аналитика промтов. В качестве примера можно привести работу с Langfuse: с его помощью мы анализируем трейсинги, отслеживаем ключевые метрики, измеряем время выполнения запросов и проводим A/B-тестирование. Управление релизами строится на четкой стратегии: если мы внедряем новый функционал, то сначала выкатываем обновление на ограниченную группу пользователей, собираем метрики и только после этого распространяем на всю аудиторию. Такой подход позволяет минимизировать риски и делает релизы предсказуемыми.
При тестировании мы используем логи и на их основе формируем синтетические сценарии, добавляем дополнительные запросы к уже известным кейсам и проверяем систему в разных условиях. После деплоя доработки продолжают находиться под постоянным мониторингом. При этом проблемы всё равно остаются: мы регулярно сталкиваемся с галлюцинациями, дрифтом промтов и особенностями работы RAG, что требует отдельного внимания и корректировок.
Как бороться с «галлюцинациями» и сохранять качество
С этой проблемой мы рекомендуем работать на низкой температуре и при необходимости подключать дополнительную цепочку проверки. Это подходит для сценариев, где скорость инференса и количество токенов не критичны. Однако в задачах реального времени, например в чат-ботах, где пользователь ждёт быстрый ответ, такие дополнительные шаги мало помогают — здесь важна именно скорость генерации.
На этом этапе большую роль играет UX-специалист. Он определяет, в каком формате нужно отвечать, где добавить call-to-action, а где уточняющий вопрос вроде «Поняли ли вы меня?». Иногда полезно завершать ответ инструкцией: «Если возникнут вопросы, напишите такому-то человеку или позвоните по телефону».
Мы для себя выработали подход, при котором не все задачи возлагаются на модель. Если нужно добавить стандартные уточнения или шаблонные инструкции, это проще сделать программно в конце генерации. Такой метод экономит токены, ускоряет работу и гарантирует, что пользователь всегда получит корректный фиксированный ответ. Например, если система не может дать нужный результат, она автоматически предлагает обратиться в службу поддержки.
А что в итоге?
Мы пришли к важному выводу: метрики важнее гипотез. Гипотезы нужно проверять быстро, а их ценность подтверждать цифрами. Успех возможен только при постоянных итерациях и регулярном фидбэке — ежедневном, еженедельном. Сегодня индустрия находится на стадии, когда единого правильного пути ещё нет. У команд есть лишь небольшой накопленный опыт, метрик ещё не так много, и именно поэтому важно пробовать разные подходы, учиться на результатах и постепенно выходить к работающим решениям. Всё, о чём я рассказал, — это наш собственный путь, но у других он может быть иным. Сейчас вокруг темы агентских систем идёт активный холивар, и это, на мой взгляд, здорово: мы все выступаем в роли исследователей, а значит, у каждой команды есть шанс придумать решение, которое окажется лучше других.






