Как закрыть страницу от индексирования: 7 проверенных способов

Если любой другой открытый для сканирования источник ссылается на страницу, которую вы заблокировали через robots.txt, она все-таки попадет в индекс. При этом у нее будет сокращенный сниппет — без доступа к контенту поисковику неоткуда взять описание.
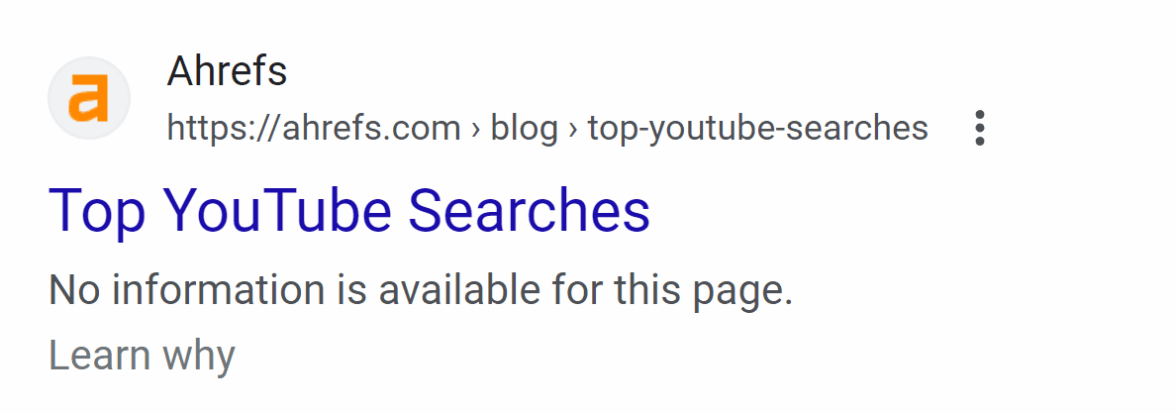
Страницу нельзя сканировать, поэтому пользователи увидят ее без описания
Чтобы не случалось непредвиденных ситуаций, используйте проверенные методы для полноценного удаления страницы из выдачи.
1. Метатеги страниц и HTTP-ответов
В HTML-коде страниц можно прописать метатеги, которые укажут роботам правильное поведение. Закрыть страницу от индексирования поможет параметр noindex для тега Robots:

Такой же параметр можно прописать на уровне заголовка HTTP-ответа с помощью X-Robots-Tag. Это работает как для страниц, так и для любых файлов на вашем сервере:

Учтите, что для того, чтобы этот метод работал, роботы должны просканировать страницу. Это значит, что noindex не будет работать одновременно с Disallow в robots.txt — убедитесь, что страница разрешенная для посещения краулерами.
2. Теги noindex и noscript
Яндекс позволяет запретить индексацию части текста на странице, если она выделена тегами noindex или noscript. Теги отличаются тем, что noscript скрывает информацию не только от поисковиков, но и от пользователей, если их браузер поддерживает JavaScript.

Способ полезный, но ограничен только российским поисковиком — Google эту инструкцию проигнорирует.
3. Запретите переход по ссылкам
Чтобы надежнее защитить страницу, заблокированную через robots.txt, можно запретить роботам переходить по ссылкам на нее, расположенным на вашем сайте. Для этого можно использовать атрибут rel=»nofollow», который нужно будет указать для каждой ссылки:

Также запрет переходить по ссылкам можно назначить для страницы целиком. Для этого используйте атрибут “nofollow” в метатеге Robots:

Здесь тоже не без минусов — запретить переход по ссылкам получится только на страницах, к которым у вас есть доступ. Если на закрытую от сканирования страницу ссылается сторонний сайт, остается шанс, что она окажется проиндексирована.
4. Установите HTTP-статус
Чтобы закрыть страницу, можно установить один из статусов HTTP:
— 401 Unauthorized: у пользователя нет прав для посещения ресурса;
— 403 Forbidden: ресурс закрыт, даже если у пользователя есть нужные права;
— 404 Not Found: запрашиваемый ресурс не найден на сервере.
Эти HTTP-ответы надежно блокируют страницы от сканирования, но одновременно делают их недоступными для просмотра обычными пользователями — учитывайте это при настройке.
Подключите свой сайт к нашей SEO-платформе, чтобы отслеживать позиции и выявлять ошибки с максимальным комфортом. Вы будете получать уведомления обо всех изменениях на вашем сайте в течение суток — еще до того, как проблема станет серьезной.
5. Удалите страницу
Иногда мы не хотим сканировать страницу из-за того, что она утратила актуальность: офисы закрываются, контакты меняются, товары заканчиваются.
Взвесьте все за и против — полезнее ли будет пытаться спрятать устаревшую информацию из выдачи или проще избавиться от нее целиком. Возможно, удаление страницы сократит количество затрат и сэкономит усилия вебмастера.
6. Закройте страницу паролем
Если блокировка или удаление — не вариант, воспользуйтесь другим способом ограничения доступа к сайту или его отдельным страницам. Вход по паролю — обычное дело для личных кабинетов и других частей сайта, в которых хранятся чувствительные данные.
Также пароль пригодится для тестовой версии сайта. Домен с готовящейся версией можно закрыть от посторонних при помощи заглушки с просьбой войти в систему как администратор — это надежно сохранит процесс от чужих глаз.
7. Воспользуйтесь инструментами для удаления из индекса
Если вы запретили индексацию страницы или вовсе удалили ее с сайта, но она продолжает появляться в результатах поиска, это значит, что поисковики еще не удалили ее из своих индексов. Ускорить этот процесс можно с помощью специальных инструментов от Яндекс и Google.
Яндекс Вебмастер
В Яндексе это можно сделать с помощью Вебмастера:
— Откройте страницу инструмента.
— Введите ссылку в поле.
— Нажмите Удалить.
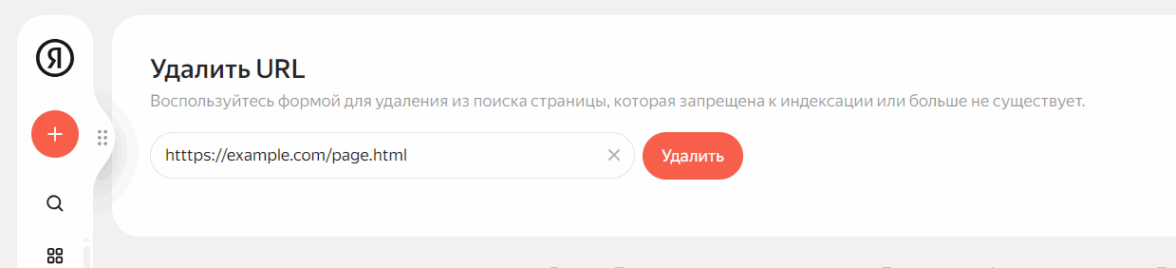
Интерфейс формы для удаления ссылок в Вебмастере
После отправки запроса Вебмастер покажет статус заявки: «В очереди», «В процессе», «Удалена». Если робот выяснит, что страница все еще доступна, он откажется удалять ее из выдачи и отклонит заявку. Прежде чем использовать этот инструмент, закройте тот же URL в robots.txt или убедитесь, что она возвращает один из кодов 401, 403 или 404.
Google Search Console
В Google существует похожий инструмент удаления URL.
— Откройте инструмент.
— Перейдите на вкладку Временные удаления.
— Нажмите Создать запрос.
— Выберите один из вариантов: Временное удаление URL (влияет на ссылку целиком и приводит к исключению страницы) или Удаление фрагмента страницы в поиске (заставляет просканировать страницу заново, чтобы заменить описание в сниппете).
— Нажмите Далее и подтвердите отправку запроса.
Search Console также показывает статус запроса в процессе обработки и тоже может отклонить заявку, предоставив подробный отчет о своем решении.
Google называет удаление временным, потому что оно действует всего 6 месяцев — после этого срока страница возвращается в выдачу. Чтобы удалить информацию навсегда, воспользуйтесь одним из указанных выше методов — запретите сканирование страницы, закройте ее от посещений или удалите.
Подписывайтесь на наш ВК и Телеграм, чтобы узнавать последние новости SEO и нейросетей, а еще подсматривать новые фишки продвижения.




