Отказать соцсетям в использовании своего контента для тренировки ИИ почти невозможно

Иллюстрация сгенерирована ChatGPT 5.5. Промпт: Артемий Шохор
Исследование показало, что большинство платформ не предлагают пользователям простой кнопки отключения передачи данных для ИИ. Вместо этого компании отправляют пользователей в разделы с политикой конфиденциальности, формы обращений и юридические документы. В ряде случаев возможность отказаться от использования данных зависит от страны проживания и местного законодательства.
Самыми закрытыми с точки зрения отказа от обучения ИИ аналитики назвали TikTok, Facebook* и Instagram*. Для Facebook и Instagram процесс отказа требует восемь действий, включая переходы по разделам настроек и заполнение специальных форм. При этом компании Meta** могут не удовлетворять такие запросы в странах, где отсутствуют законы, аналогичные европейскому GDPR (General Data Protection Regulation — действующий в Евросоюзе закон о защите персональных данных, который обязывает компании раскрывать, как они используют информацию о пользователях, и дает гражданам право требовать ограничить или запретить обработку своих данных). Авторы исследования отмечают, что наилучшая защита сегодня действует для пользователей из Евросоюза, Европейской экономической зоны и Великобритании.
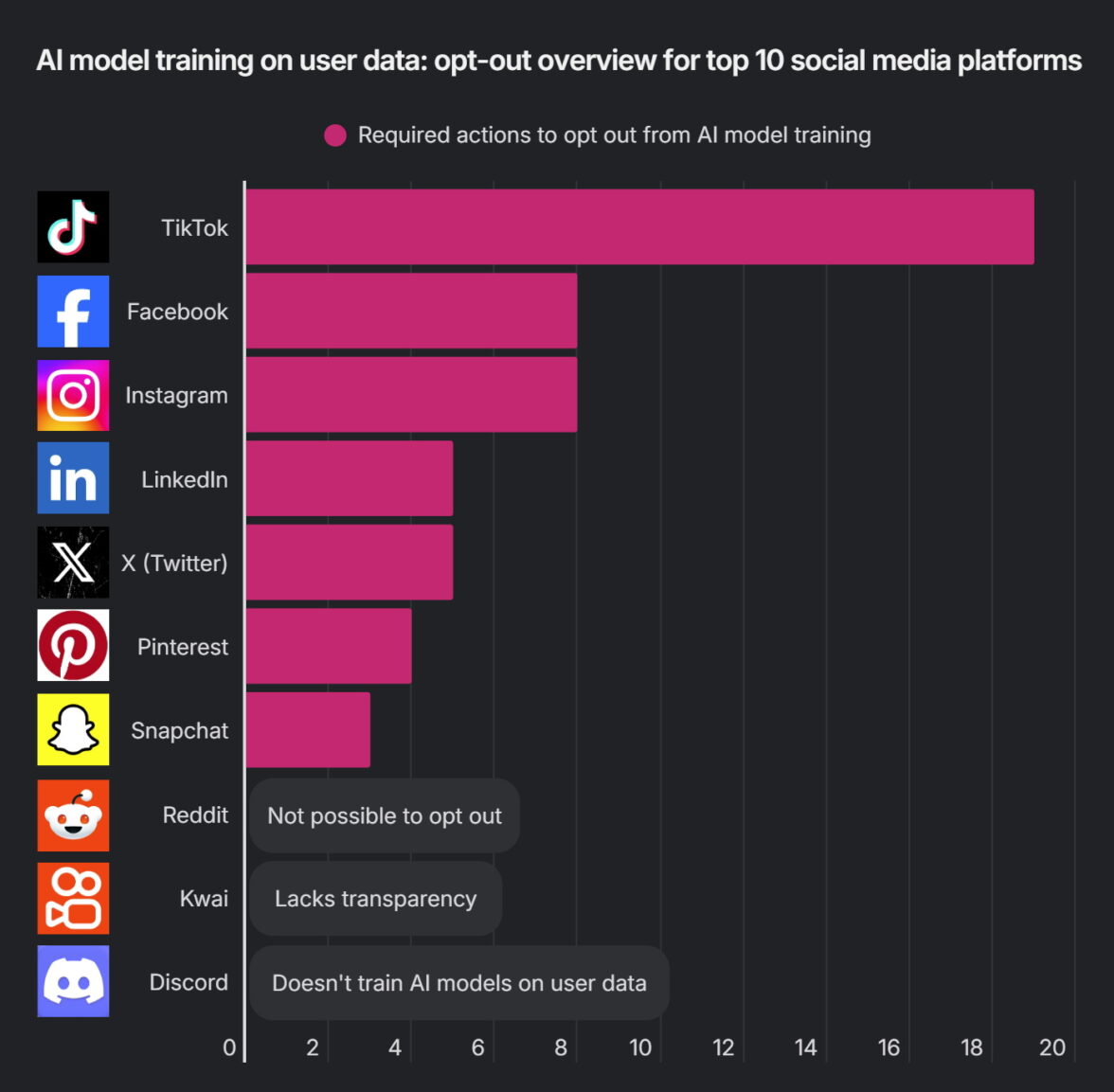
Для отказа от использования пользовательских данных при обучении ИИ TikTok требует 19 действий, Facebook и Instagram — по 8, LinkedIn и X — по 5, Pinterest — 4, Snapchat — 3. Reddit не предоставляет возможности отказаться вовсе, Kwai не раскрывает детали работы с ИИ, а Discord заявляет, что не использует данные пользователей для обучения нейросетей. Инфографика: Surfshark.
На другом полюсе оказались Snapchat, LinkedIn, X и Pinterest. Эти платформы позволяют отключить использование данных для ИИ через настройки приложений за три-пять действий. Однако по умолчанию функция согласия уже включена. Если пользователь заранее не отключил ее, его публикации, вероятно, уже использовались для обучения алгоритмов. При этом отказ действует только на будущее использование данных.
Отдельно аналитики выделили Reddit. Платформа вообще не предоставляет пользователям возможности отказаться от обучения ИИ на их публикациях. В исследовании напоминается, что в 2024 году Reddit заключил соглашения с Google и OpenAI на сумму около $203 млн, предоставив компаниям доступ к массивам пользовательских обсуждений для обучения нейросетей. Одновременно Reddit запрещает сторонний несанкционированный сбор данных, но самостоятельно лицензирует контент крупным ИИ-компаниям.
Авторы исследования также обратили внимание, что часть платформ использует не только публичные, но и приватные данные. Например, TikTok, Pinterest и LinkedIn оставляют за собой право обучать модели ИИ как на открытых публикациях, так и на личных данных пользователей. TikTok, по данным Surfshark, может анализировать даже не опубликованные черновики видео.
Из десяти исследованных платформ только Discord прямо заявил, что не использует пользовательские данные для обучения ИИ. В отношении китайско-бразильской платформы Kwai аналитики отметили недостаток прозрачности.
Как проводилось исследование
Surfshark проанализировала десять крупнейших социальных платформ по данным Cloudflare о трафике и пользовательской активности. Аналитики изучали мобильные приложения соцсетей, проверяли настройки согласия на обучение ИИ и подсчитывали количество действий, необходимых для отказа. За отдельное действие принимались нажатия кнопок, переходы по меню, ввод данных и переключение настроек. Для Reddit, Discord и Kwai дополнительно изучались официальные политики конфиденциальности и публичные заявления компаний.
* продукт компании Meta (признана экстремистской организацией и запрещена в РФ)
** признана экстремистской организацией и запрещена в РФ
в Telegram канале





