Как обнаружить и ликвидировать дубликаты страниц сайта: подробная инструкция для бизнеса
По статистике, от 65 до 80% всех веб-ресурсов сталкиваются с этой проблемой, даже не подозревая о ней. При этом потери трафика могут достигать 30–50%, а краулинговый бюджет расходуется впустую на 25–40%.
Многие владельцы бизнеса уверены, что главное в продвижении сайта — это ключевые слова и ссылки. Однако алгоритмы Яндекса и Google в последнее время стали особенно чувствительны к повторяющемуся контенту. Даже частичные дубли способны серьёзно навредить видимости вашего ресурса в поисковой выдаче.
Представитель Google Джон Мюллер неоднократно подчёркивал: поисковые системы не штрафуют за дубли напрямую, однако они вынуждены выбирать, какую версию страницы показывать пользователям. И этот выбор может оказаться не в вашу пользу.

Какие виды дублей существуют
Полные дубликаты
Это страницы с тем же самым контентом, но разными адресами. Типичные причины:
-
варианты домена с префиксом www и без него (www.site.ru / site.ru)
-
разные схемы подключения (http и https)
-
URL с завершающим слэшем и без слэша
-
адреса с индексными файлами вида index.html или index.php
-
отличия в регистре пути (site.ru/about/ против site.ru/ABOUT/)
-
URL с добавленными GET‑параметрами и UTM‑метками.
Так, чистый линк, ведущий на главную страницу сайта (site.ru) и та же страница с добавленным параметром utm_source=google в строке запроса (site.ru/?utm_source=google) формально различаются, но приводят пользователя на один и тот же URL с идентичным контентом.
Частичные дубликаты
В группу частично дублирующихся материалов попадают страницы, где значительная часть содержимого повторяется, но есть отличия. В эту группу попадают, например, страницы, которые появляются после применения пользователем сортировки и параметров фильтрации товаров, отдельные карточки одинаковых товаров с различными параметрами, отдельные URL внутри пагинации одного раздела и их варианты, ориентированные на разные географические зоны с локализованным содержанием.
Семантические дубли
Это страницы, отличающиеся текстом, но при этом SEO-оптимизированные под одинаковую группу запросов и решающие одну и ту же задачу пользователя. Так, /nozhi-dlya-kuhni/ и /kuhonnie-nozhi/ для поисковиков представляют собой разные варианты ответа на единственный поисковый интент.
Если совпадение значительной части ключевых запросов превышает 70%, такие страницы с высокой вероятностью конкурируют между собой.
Почему появляются дубли: главные причины
Дублированные страницы возникают по нескольким причинам, и часто это происходит незаметно для владельца сайта:
Особенности CMS. WordPress, Битрикс, Joomla и другие системы управления контентом автоматически генерируют страницы, ведущие на один и тот же товар, но имеющие разные URL. Особенно часто это встречается в интернет-магазинах, где одна и та же позиция может попадать в несколько разделов.
Некорректная настройка редиректов. При переезде сайта на https или смене структуры старые страницы остаются доступными без перенаправления.
Ошибки в файле robots.txt. Неправильные директивы позволяют роботам индексировать служебные страницы.
GET-параметры. Фильтры, сортировки, идентификаторы сессий добавляют к URL параметры, создавая десятки копий одной страницы.
Человеческий фактор. Контент-менеджер может добавить один товар в несколько категорий или продублировать описание услуги.
Отдельную проблему представляют dev-, test- и staging‑версии сайта на отдельных поддоменах, оставленные открытыми для роботов из‑за того, что разработчики не настроили запрет индексации.
Влияние дублированного контента на эффективность SEO‑оптимизации и рост видимости ресурса

Комплекс технических работ по внутренней настройке ресурса напрямую связан с ликвидацией дублированных страниц. Вот какие проблемы они создают:
Размывание ссылочного веса
В подобных случаях PageRank не концентрируется на единственной странице, а делится между разными адресами, ведущими на схожий контент. Для бизнеса это чувствительно: внешние ссылки формируют ссылочный профиль, который напрямую воздействует на ранжирование и видимость ресурса в поисковиках.
Каннибализация ключевых слов
Дубли конкурируют друг с другом за одинаковые запросы. В результате поисковик не может определить, какую страницу показывать, и в результате обе теряют позиции.
Перерасход краулингового бюджета
Для каждого домена робот задаёт собственный «тайм‑слот» обхода. При большом количестве дублей он тратит его на второстепенные копии, а не на ценные документы, из‑за чего индексирование критически важных разделов заметно замедляется относительно нормальной скорости.
Путаница в аналитике
Трафик распределяется между копиями страниц, а это затрудняет оценку эффективности контента и принятие маркетинговых решений.
Инструменты для поиска дублей: полный арсенал
Панели вебмастеров
Найти дубли реально прямо в интерфейсе Яндекс Вебмастера. Зайдите в раздел «Индексирование», далее выберите «Страницы в поиске» → «Исключённые» используйте фильтр «Дубль». Также полезен раздел «Заголовки и описания», демонстрирующий URL с повторяющимися метатегами. Недавно Яндекс добавил специальное уведомление в разделе «Диагностика», которое автоматически сообщает о значительной доле дублей.
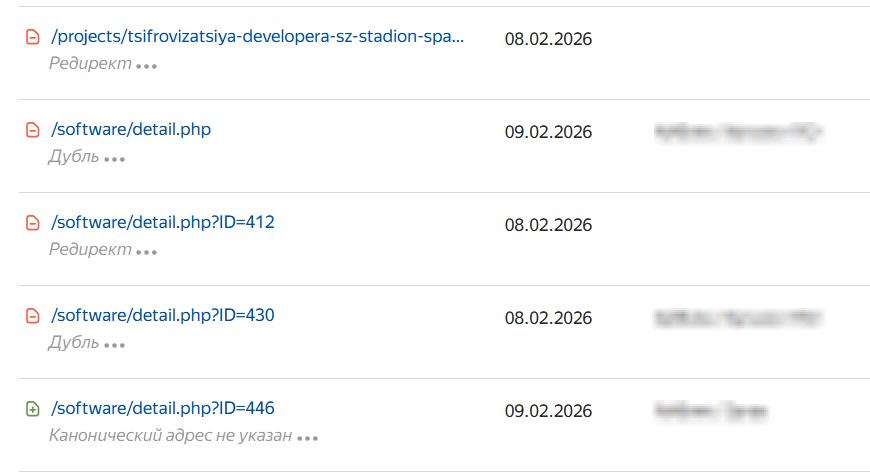
Google Search Console отображает сведения в разделе «Покрытие» → «Исключено». В списке адресов приоритетно анализируйте записи с меткой «Страница является копией. Канонический вариант не выбран пользователем» и «Альтернативная страница с правильным каноническим тегом», поскольку они напрямую связаны с дублированным контентом и выбором канонической версии.
Специализированные программы
Screaming Frog SEO Spider считается отраслевым стандартом для технического SEO-аудита: он полноценно сканирует сайт и помогает быстро найти страницы с дублирующимися Title, Description и заголовками H1. Функция Near Duplicates позволяет найти страницы со схожестью контента от 70% до 100%. Для настройки перейдите в Configuration → Content → Duplicates и установите порог схожести.
Netpeak Spider — отличная альтернатива с русскоязычным интерфейсом. Выявляет страницы, где контент совпадает на 100%, дубли по содержимому блока body, повторяющиеся метатеги.
SiteAnalyzer — бесплатное решение, которое показывает дубликаты по title, description и заголовкам h1-h6.
Поисковые операторы
Для быстрой проверки используйте специальные операторы:
-
Запрос site:domain.ru «уникальный фрагмент текста» помогает отловить дубликаты текстов внутри границ одного сайта.
-
Конструкция allintitle:»ключевая фраза» site:domain.ru используется для выявления повторяющихся заголовков на разных страницах сайта.
-
Оператор inurl:?parameter site:domain.ru применяют чтобы отследить ссылки с параметрами, которые часто создают технические дубли.
Методы ликвидации дублирующих страниц: от простого к сложному
301 редирект — самый надёжный способ
Корректно прописанный 301‑редирект «склеивает» страницы: ссылки, ведущие на сайт со сторонних доменов и их вес перераспределяются в пользу основной версии, практически без потерь. В итоге краулинг и трафик концентрируются на каноническом URL, а дубликаты постепенно деиндексируются — обычно это занимает от одной до двух недель при нормальном краулинговом бюджете.
Когда использовать:
Склейка зеркал www и без www
Переезд с http на https
Объединение страниц со слэшем и без слэша
Удаление устаревших URL при изменении структуры
Важно избегать цепочек редиректов длиннее 3 переходов — это снижает скорость обхода сайта поисковыми ботами и снижает эффективность передачи веса.
Атрибут rel=«canonical»
С помощью тега canonical вы явно указываете поисковым системам, какая версия страницы – основная и должна ранжироваться. Для этого соответствующий <link rel=»canonical»> прописывается в блоке <head> дублирующих документов:
<link rel=»canonical» href=»https://site.ru/main-page/» />
Метод удобен тем, что вы не ломаете навигацию и UX: пользователи по-прежнему могут заходить на любые варианты страниц, в то время как поисковики консолидируют вес и показывают в выдаче только каноническую версию. Для страниц фильтрации и сортировки это один из наиболее безопасных способов ликвидации дублей.
Часто встречающиеся ошибки при настройке canonical:
К критичным промахам относятся: прописывание canonical через относительный путь, добавление тега в секцию <body>, ссылка на URL с ответом 404, дублирование нескольких canonical‑теговнаодной странице и перенаправление всего раздела (категории) на отдельный товар.
Google отдельно предупреждает, что когда основная страница и её «копии» не эквивалентны по содержанию, поисковая система может не принять во внимание заданный вами rel=»canonical» и выбрать канон по собственным сигналам.
Специальная инструкция Clean-param для Яндекса
В robots.txt допускается задать список «безопасных» GET‑параметров через Clean-param, например:
Clean-param: utm_source
Clean-param: sort
Clean-param: filter
Так Яндекс понимает, что UTM‑метки и параметры фильтрации/сортировки не должны порождать уникальные URL, и перестаёт создавать по ним дубли в индексе; Гугл и иные поисковики на эту директиву не реагируют.

Правило Disallow, прописанное в robots.txt для запрета обхода отдельных URL или каталогов
Блокирует обход поисковыми роботами определённых URL:
User-agent: *
Disallow: /*?sid=
Минус такого решения в том, что запреты в robots.txt сами по себе не гарантируют отсутствия URL в поисковой выдаче: страницы с параметром sid всё равно могут индексироваться за счёт внешних ссылок, в такой конфигурации «запертые» страницы не участвуют в перераспределении ссылочного авторитета в пользу целевых URL.
Метатег noindex
Он запрещает добавлять конкретный URL в индекс:
<meta name=»robots» content=»noindex, follow»>
Однако использовать этот подход как базовое решение проблемы дублей нежелательно — подобные URL не усиливают важные страницы ссылочным авторитетом, при этом роботы продолжают тратить ресурсы сканирования на их обход.
Особенности работы с пагинацией
Страницы пагинации — частый источник частичных дублей. Google рекомендует, чтобы каждая страница в теге canonical прописывала именно себя как каноническую версию. Яндекс же более строг: для него оптимально запретить индексирование (через noindex, follow) всех последующих страниц, оставив индексируемой исключительно первую.
Обязательно уникализируйте метатеги:
Добавляйте указание номера в теге Title: «Блог — страница 2 из 19»
Формируйте уникальные Description с указанием диапазона товаров
Размещайте SEO‑текст лишь на первой странице выдачи товаров в категории.
Чек-лист профилактики: какие меры принять, чтобы не допустить формирования дублей
Логичнее сразу выстроить архитектуру и настройки так, чтобы дубли просто не возникали, чем потом вести долгую борьбу с уже сформировавшимися копиями страниц:
-
Настройте человекопонятные URL и продуманную иерархию адресов страниц.
-
Подключите SEO‑плагины, которые автоматически проставляют canonical‑теги на страницах
-
Настройте редиректы между www/без www и http/https до наполнения контентом
-
Закройте тестовые поддомены от индексации
-
Внедрите автоматическое присвоение canonical для товаров в нескольких категориях
-
Корректно обрабатывайте GET-параметры
Имеет смысл включить режим обнаружения дубликатов в плановый SEO-аудит сайта и выполнять его регулярно — от одного раза в месяц до одного раза в квартал, исходя из того, как часто вы обновляете контент.
Реальные результаты: что даёт устранение дублей
Практика показывает, что системная работа с дублями приносит измеримые результаты. В одном из кейсов после удаления 12 000 дублирующихся страниц интернет-магазин вошёл в ТОП Яндекса за три месяца. Другой проект зафиксировал рост органического трафика на 35% после переписывания дублирующихся описаний товаров.
Устранение технических дублей (www/без www, http/https, слэши) даёт самый быстрый эффект и требует минимальных усилий. Это первое, с чего стоит начать SEO оптимизацию сайта любому бизнесу.
Дублированные страницы — это скрытая, но решаемая проблема. Регулярный мониторинг, правильный выбор инструментов и последовательное применение методов устранения позволяют не только избежать санкций со стороны поисковых систем, но и значительно улучшить позиции сайта в выдаче. Инвестиции в техническую оптимизацию окупаются ростом органического трафика и конверсий.